TL;DR — 用途別ベスト方法 10 秒早見表
- 今すぐ変換したい・インストール不要 → FormatArc CSV to JSON (ブラウザ完結、アップロード不要、UTF-8 / Shift-JIS / クォート / 埋め込み改行に対応)
- シェルスクリプト・ワンライナー →
csvjson data.csv(csvkit) またはmlr --icsv --ojson cat data.csv(Miller) - Python アプリ内 →
csv.DictReader(標準ライブラリ、依存ゼロ) または大規模ファイルはpandas.read_csv - Node.js アプリ内 → PapaParse の
{ header: true, dynamicTyping: true } - Go サービス内 →
encoding/csv+ headers → map のループ - 大規模ファイル (100 万行以上) →
csv.DictReaderで行ごとに NDJSON 出力。json.dumpでリスト一括出力は禁止
| 方法 | セットアップ | 大規模ファイル対応 | 型推論 | NDJSON 出力 |
|---|---|---|---|---|
| FormatArc ブラウザ | なし | 50 MB 程度 (ブラウザメモリ依存) | あり (オプション) | なし (CLI 推奨) |
Python csv.DictReader |
標準ライブラリ | あり (手書きループ) | なし (全て文字列) | あり |
pandas read_csv |
pip install pandas |
chunksize= でストリーミング |
あり (dtype 自動推論) |
あり (lines=True) |
Miller (mlr) |
brew install miller |
あり (完全ストリーミング) | あり (--inumeric) |
あり (--ojsonl) |
csvkit (csvjson) |
pip install csvkit |
なし (全件ロード) | あり (--no-inference で無効化) |
なし |
| PapaParse (Node) | npm install papaparse |
あり (step コールバック) |
あり (dynamicTyping) |
あり (手書き) |
Go encoding/csv |
標準ライブラリ | あり (Read ループ) | なし (手動キャスト) | あり (手書き) |
本記事では各方法をコード付きで紹介したあと、4 つのハマりどころ (出力形式・エンコーディング・型推論・大規模ファイル処理) を実例で解説します。
CSV 形式のおさらい (RFC 4180)
CSV (Comma-Separated Values) は RFC 4180 で非公式に規定されたテキスト形式ですが、実際の現場ではさまざまな方言が存在します。典型的な CSV:
name,email,department,start_date
Alice Johnson,alice@example.com,Engineering,2024-01-15
Bob Smith,bob@example.com,Marketing,2023-06-01
Carol Williams,carol@example.com,Engineering,2024-03-10
1 行目はヘッダー (列名)、2 行目以降がデータです。フィールドはカンマで区切られますが、シンプルな見た目に反していくつかの落とし穴があります。
- カンマを含むフィールドはダブルクォートで囲む:
"Smith, John" - ダブルクォートを含むフィールドは 2 重化でエスケープ:
"She said ""hello""" - クォート内の改行は有効 (素朴なパーサーでよく壊れる原因)
- エンコーディングに標準なし。UTF-8 / Latin-1 / Shift-JIS / BOM 付き UTF-8 など、出力元次第 (Windows の Excel はデフォルトで BOM 付き UTF-8)
- 区切り文字も標準化されていない。TSV はタブ、ヨーロッパの Excel は
;、科学データセットでは|が使われることもある
CSV の歴史や仕様の詳細は CSV とは を参照してください。
なぜ CSV を JSON に変換するのか
実務でよく出てくる理由をまとめます。
- REST API: API はリクエストボディに JSON を要求する。CSV で管理しているデータを API に POST するには変換が必要
- フロントエンド: React / Vue / Svelte は JSON 配列・オブジェクトを自然に扱える。ブラウザで CSV をパースするのは可能だが、依存が増える
- 型情報の保持: CSV は全て文字列。JSON は number / boolean / string / null を区別できる
- NoSQL データベース: MongoDB / CouchDB / DynamoDB のバルクローダーは JSON Lines (NDJSON) を直接読める
- データパイプライン: Apache Airflow / Prefect / Mage / dbt などのワークフローツールはステージ間の交換フォーマットとして JSON / NDJSON を要求する場面が増えている
- LLM コンテキスト: 表データを LLM に渡す際、CSV より JSON オブジェクトのほうがキー認識が安定する。詳しくは LLM に Markdown vs HTML を渡すなら を参照
両形式の違いについては JSON とは で詳しく解説しています。
5 種類の JSON 出力形式
CSV から JSON に変換するツールのほとんどは「ヘッダーをキーとするオブジェクトの配列」一択です。それで足りる用途が半分、足りない用途が半分というのが実情。同じ CSV を 5 種類すべての形式に変換した例を見てください。
入力 CSV:
id,name,score
1,Alice,95
2,Bob,87
3,Carol,92
形式 1: オブジェクトの配列 (大半のツールのデフォルト)
[
{ "id": 1, "name": "Alice", "score": 95 },
{ "id": 2, "name": "Bob", "score": 87 },
{ "id": 3, "name": "Carol", "score": 92 }
]
用途: REST API、フロントエンド描画、汎用的なデータ交換。
形式 2: Keyed オブジェクト (特定列を主キーに)
{
"1": { "name": "Alice", "score": 95 },
"2": { "name": "Bob", "score": 87 },
"3": { "name": "Carol", "score": 92 }
}
用途: ルックアップテーブル、ID で辞書アクセスしたい場合。Python で生成:
import csv, json, sys
rows = list(csv.DictReader(sys.stdin))
result = {row["id"]: {k: v for k, v in row.items() if k != "id"} for row in rows}
json.dump(result, sys.stdout, indent=2)
形式 3: JSON Lines / NDJSON (改行区切り JSON)
{"id":1,"name":"Alice","score":95}
{"id":2,"name":"Bob","score":87}
{"id":3,"name":"Carol","score":92}
用途: ストリーミング取り込み (BigQuery / Snowflake COPY INTO / MongoDB mongoimport --type=json / ログパイプライン / Kafka producer)。1 行 1 レコードで独立してパース可能なので、10 GB のファイルでもメモリに乗せずに処理できます。
生成: mlr --icsv --ojsonl cat data.csv (Miller) または jq -c '.[]' array.json > lines.ndjson。
形式 4: 列指向 (並列配列)
{
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Carol"],
"score": [95, 87, 92]
}
用途: データサイエンス (Apache Arrow / pandas 内部レイアウトと一致)、GPU パイプライン、列指向データベース。pandas で生成: df.to_dict(orient="list")。
形式 5: スラッシュ区切りヘッダーでネスト化
入力 CSV (ヘッダーをスラッシュ区切りにする):
id,name,address/city,address/zip
1,Alice,Tokyo,150-0001
2,Bob,Osaka,530-0001
出力 (ネスト):
[
{ "id": 1, "name": "Alice", "address": { "city": "Tokyo", "zip": "150-0001" } },
{ "id": 2, "name": "Bob", "address": { "city": "Osaka", "zip": "530-0001" } }
]
用途: ネスト構造を要求する API リクエストボディの生成。大半のツールは後処理が必要 (後述の ネスト JSON の生成 を参照)。
方法 1: FormatArc ブラウザツール (アップロード不要)
今すぐ変換したい、インストールなしで済ませたい場合は CSV to JSON が最速です。すべてブラウザ内で処理されるので、データは一切外部に送信されません。
- CSV to JSON を開く
- 左側のエディタに CSV を貼り付ける
- 「変換」ボタンを押すと、右側に JSON が表示される
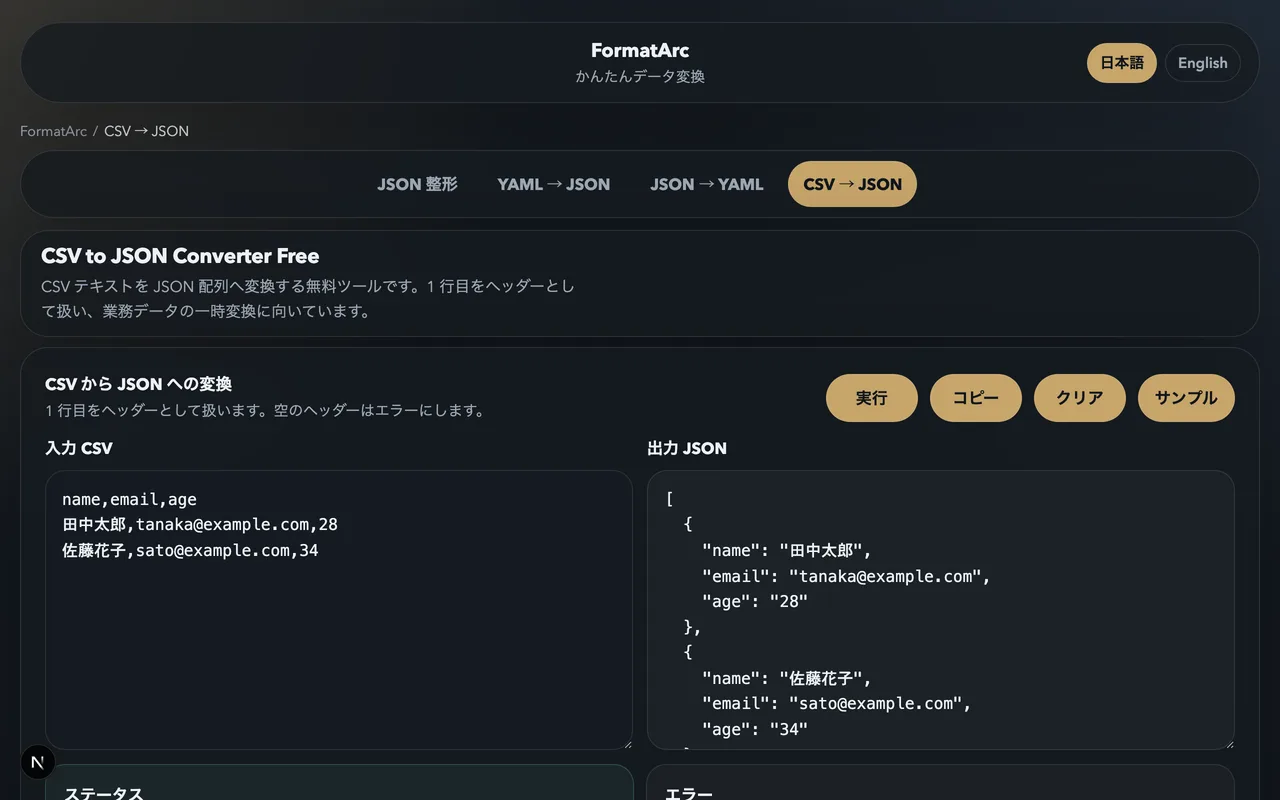
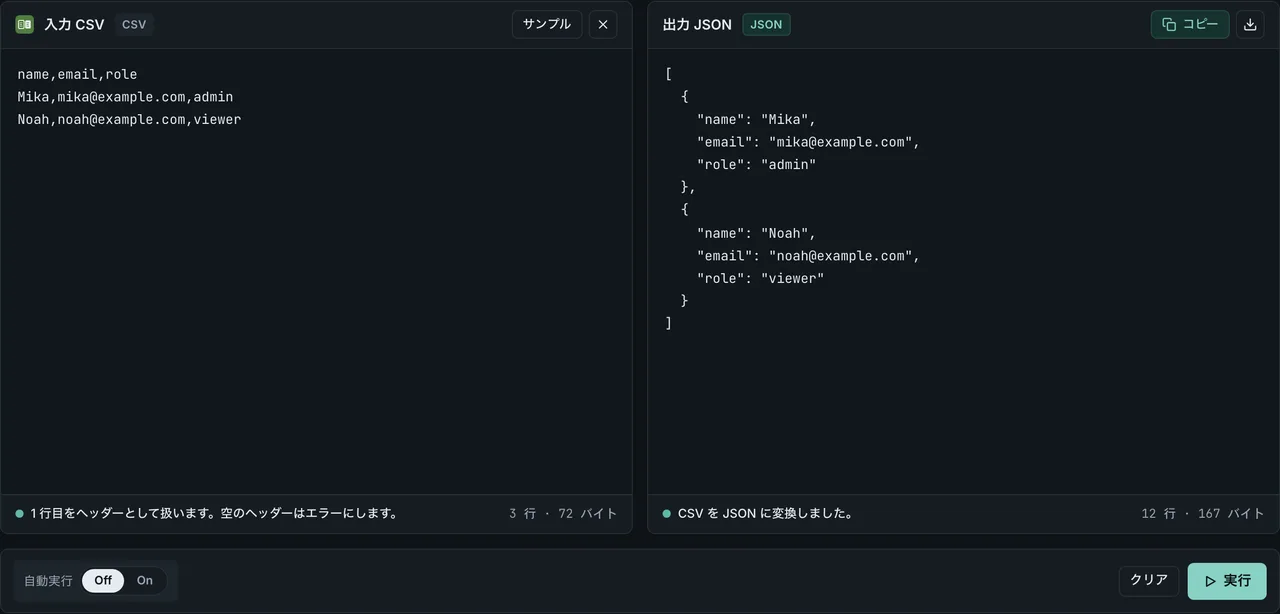
素朴なパーサーでハマりがちな箇所もきちんと処理します。クォート付きフィールドのカンマ、改行を含むフィールド、空のフィールド (空文字列に変換)、大規模データセット (ブラウザメモリ次第ですが概ね 50 MB / 50 万行までは安定)。
ブラウザ内処理は機密データを扱うときに効きます。顧客情報、給与テーブル、vault からエクスポートした API キー、社内の財務データなど、貼り付けたデータはタブの中だけで完結します。アップロード処理もサーバー側処理もありません。
方法 2: Python — csv.DictReader と pandas
Python は csv と json を標準ライブラリに含むので、基本的な変換だけならサードパーティ不要です:
import csv
import json
import sys
reader = csv.DictReader(sys.stdin)
rows = list(reader)
json.dump(rows, sys.stdout, indent=2, ensure_ascii=False)
csv2json.py として保存して実行:
python3 csv2json.py < data.csv > data.json
csv.DictReader は 1 行目をヘッダーとして自動認識します。各行が dict になり、dict のリストがそのまま JSON のオブジェクト配列に対応します。ensure_ascii=False は CSV に日本語やアクセント付き文字、絵文字が含まれる場合に重要。これを忘れると あ のような Unicode エスケープシーケンスになります。
pandas を使う (大規模ファイル + 型推論)
import pandas as pd
df = pd.read_csv("data.csv", encoding="utf-8")
df.to_json("data.json", orient="records", indent=2, force_ascii=False)
orient="records" でオブジェクト配列出力。他に "index" (Keyed オブジェクト)、"columns" (列指向)、"values" (配列の配列) があります。
メモリに乗らないファイルは chunksize でストリーミング:
import pandas as pd
with open("output.ndjson", "w") as out:
for chunk in pd.read_csv("huge.csv", chunksize=10000):
chunk.to_json(out, orient="records", lines=True, force_ascii=False)
out.write("\n")
NDJSON 形式で出力され、メモリに乗るのは常に 10000 行だけです。
方法 3: Node.js — PapaParse
JavaScript で CSV パースといえば papaparse が定番。FormatArc のブラウザツールも内部で PapaParse を使っています。
const Papa = require("papaparse");
const fs = require("fs");
const csv = fs.readFileSync("data.csv", "utf8");
const result = Papa.parse(csv, {
header: true,
dynamicTyping: true, // "42" → 42、"true" → true
skipEmptyLines: true,
});
fs.writeFileSync("data.json", JSON.stringify(result.data, null, 2));
大規模ファイルは step コールバックでストリーミング:
const fs = require("fs");
const Papa = require("papaparse");
const stream = fs.createReadStream("huge.csv");
const out = fs.createWriteStream("huge.ndjson");
Papa.parse(stream, {
header: true,
dynamicTyping: true,
step: (row) => out.write(JSON.stringify(row.data) + "\n"),
complete: () => out.end(),
});
各行を即ディスクに書き出すので、ギガバイト級のファイルでもメモリ消費は一定。
方法 4: Go — encoding/csv
package main
import (
"encoding/csv"
"encoding/json"
"fmt"
"os"
)
func main() {
f, _ := os.Open("data.csv")
defer f.Close()
reader := csv.NewReader(f)
records, _ := reader.ReadAll()
headers := records[0]
result := make([]map[string]string, 0, len(records)-1)
for _, row := range records[1:] {
obj := make(map[string]string, len(headers))
for i, val := range row {
obj[headers[i]] = val
}
result = append(result, obj)
}
out, _ := json.MarshalIndent(result, "", " ")
fmt.Println(string(out))
}
Go の encoding/csv は全フィールドを文字列として扱います。型付きで出力したい場合は手動で strconv.Atoi / strconv.ParseFloat / strconv.ParseBool を呼びます。
大規模ファイルを扱う場合は ReadAll() を Read() ループに置き換え、1 行ずつ json.Marshal して NDJSON で書き出します。
方法 5: Miller と csvkit (ワンライナー)
シェルスクリプトでサッと変換したいときは、ワンコマンドで完結する 2 つのツールが便利です。
Miller (mlr)
Miller はストリーミング型のデータプロセッサ。構造化データ向けの awk のような位置付け:
# オブジェクト配列
mlr --icsv --ojson cat data.csv > data.json
# NDJSON (ストリーミング向き)
mlr --icsv --ojsonl cat data.csv > data.ndjson
# フィルタしながら変換
mlr --icsv --ojson filter '$score > 90' data.csv
# 変換中に列を追加
mlr --icsv --ojson put '$grade = $score >= 90 ? "A" : "B"' data.csv
インストール: brew install miller (macOS) または apt install miller (Debian / Ubuntu)。
csvkit (csvjson)
csvkit は Python 製の CSV ツールスイート:
pip install csvkit
csvjson data.csv > data.json
便利なオプション:
--indent 2— 整形出力--no-inference— 全てを文字列のまま出力 (数値の自動変換を無効化)--stream— 配列でなく NDJSON で出力--locale ja_JP.UTF-8— ロケール依存の数値パース
NDJSON でサクッと出したいだけなら csvjson --stream が最短ルート。
ネスト JSON の生成 (スラッシュ区切りヘッダー)
ほとんどのコンバータはフラットなオブジェクトを返します。下流の API / Mongo スキーマ / GraphQL リゾルバがネスト構造を要求する場合は、後処理が必要です。
ヘッダーに / や . で区切り文字を入れる慣習があります:
id,name,address/city,address/zip,address/country
1,Alice,Tokyo,150-0001,JP
2,Bob,Osaka,530-0001,JP
Python で変換 + ネスト化:
import csv, json, sys
def nest(row, sep="/"):
result = {}
for key, val in row.items():
parts = key.split(sep)
cursor = result
for part in parts[:-1]:
cursor = cursor.setdefault(part, {})
cursor[parts[-1]] = val
return result
reader = csv.DictReader(sys.stdin)
rows = [nest(r) for r in reader]
json.dump(rows, sys.stdout, indent=2, ensure_ascii=False)
出力:
[
{ "id": "1", "name": "Alice", "address": { "city": "Tokyo", "zip": "150-0001", "country": "JP" } },
{ "id": "2", "name": "Bob", "address": { "city": "Osaka", "zip": "530-0001", "country": "JP" } }
]
ドット記法 (address.city) でやりたい場合は sep="." に変えるだけ。convertcsv.com というサイトがこの / 区切りを広めた経緯があり、最大 10 階層までのネストに対応しています。
エンコーディング対応 (Shift-JIS / BOM / クォートカンマ / 埋め込み改行)
エンコーディングのズレは CSV → JSON で文字化けする原因のトップ。
UTF-8 BOM
Windows の Excel で「CSV UTF-8」を選択すると、ファイル先頭に Byte Order Mark (BOM) という 3 バイト (EF BB BF) が付きます。多くの JSON パーサーは BOM を除去しないので、最初のキーが name でなく name (見えない BOM 付き) になります。
Python で除去:
with open("data.csv", encoding="utf-8-sig") as f: # -sig が BOM を除去
reader = csv.DictReader(f)
Miller で除去: mlr --icsv --ojson cat <(sed '1s/^\xEF\xBB\xBF//' data.csv)。
Shift-JIS (日本語版 Excel デフォルト)
日本語版 Excel は「CSV UTF-8」を明示的に選ばないと Shift-JIS で出力します。出力に �� のような文字化けが出たらエンコーディングが間違っています:
with open("data.csv", encoding="shift-jis") as f:
reader = csv.DictReader(f)
シェルで一括変換: iconv -f SHIFT-JIS -t UTF-8 data.csv > data.utf8.csv。
FormatArc ブラウザツール は UTF-8 を期待しているので、Shift-JIS ファイルは事前に iconv またはテキストエディタの「別名で保存」で UTF-8 化してから貼り付けます。
Latin-1 (ヨーロッパ版 Excel デフォルト)
ヨーロッパロケールの Excel は Latin-1 (Windows-1252) で保存することがあります。Shift-JIS と同様に iconv -f LATIN1 -t UTF-8 または Python で encoding="latin-1" を指定。
クォートカンマと埋め込み改行
区切り文字を含むフィールドはクォートで囲む必要があります:
id,description
1,"Hello, world"
2,"Multi-line
description here"
素朴なパーサーは 2 行目のカンマで分割してしまい、3 行目の改行で行が切れたと誤認識します。きちんとした CSV パーサー (DictReader / PapaParse / Miller / csvkit) を使いましょう。string.split(",") を自力で書くのは禁物です。
カンマ以外の区切り文字 (; / タブ / パイプ)
ヨーロッパ Excel は ; を使うことが多い。区切り文字を明示します:
reader = csv.DictReader(f, delimiter=";")
mlr --csv --ifs ";" --ojson cat data.csv
Papa.parse(csv, { header: true, delimiter: ";" });
TSV (タブ区切り) は delimiter="\t" または Miller の --itsv。
型推論 (数値 / 真偽値 / null の解釈)
CSV は全てテキストです。JSON 出力に型を保持するかはツール次第です。
| ツール | デフォルト挙動 | 推論を有効化する方法 |
|---|---|---|
csv.DictReader (Python 標準) |
全て文字列 | 手動キャスト |
pandas read_csv |
列ごとに自動推論 | デフォルト有効、dtype=str で無効化 |
| PapaParse (Node) | 全て文字列 | { dynamicTyping: true } |
Miller (mlr) |
全て文字列 | --inumeric フラグ |
csvkit (csvjson) |
推論あり | --no-inference で無効化 |
| FormatArc ブラウザ | 全て文字列 (ラウンドトリップ安全) | n/a |
推論を有効にした場合の落とし穴:
"007"が7になる (先頭ゼロが消える。電話番号・郵便番号・ISBN で致命的)"NaN"や"Infinity"が浮動小数点になる"true"/"false"/"yes"/"no"が真偽値になる (PapaParse はtrue/falseのみ、Miller はもっと厳しい)- 空文字列
""がnull/""/ 省略 のいずれかに化ける (ツールによって挙動異なる) - 数値に見える ID 列が number に強制変換され、15 桁を超える ID で精度落ち (JavaScript の
Number.MAX_SAFE_INTEGERは2^53 - 1)
安全なデフォルト: すべて文字列のまま出力し、スキーマがわかっているアプリケーション層でキャストする。自動推論は分析用途には便利ですが、本番データパイプラインでは不安定です。
パフォーマンスと大規模ファイル
1 万行未満ならどの方法でも実用速度です。差が出てくるのは大規模ファイル。
| ファイルサイズ | 推奨方法 | 理由 |
|---|---|---|
| 10 MB 未満 | ブラウザツール / csvkit / pandas | メモリに余裕で収まる |
| 10〜500 MB | pandas chunksize / Miller / PapaParse stream / Go |
1 行ずつ処理、全件ロード不要 |
| 500 MB 以上 | Miller / Go / Python csv.DictReader + NDJSON 出力 |
定数メモリでのストリーミング必須 |
ベンチマーク目安 (2024 年 M3 MacBook、1 スレッド、5 列 CSV):
csv.DictReader+json.dump: 約 150,000 行/秒- pandas
read_csv+to_json: 約 400,000 行/秒 (pandas 2.0 で Arrow backed 化されて高速化) - Miller
mlr --ojsonl: 約 600,000 行/秒 (Go 実装) - Go
encoding/csv+ 手書きマーシャラー: 約 800,000 行/秒 - PapaParse streaming (Node): 約 250,000 行/秒
- ブラウザ FormatArc: メモリ依存、概ね 50 MB / 50 万行まで
テラバイト級になるとこれらは適材適所ではありません。Apache Spark、DuckDB (COPY data FROM 'data.csv' (FORMAT CSV) → COPY (SELECT * FROM data) TO 'out.ndjson' (FORMAT JSON, ARRAY false))、Apache Arrow を直接使うのが妥当。
任意サイズのファイル用ストリーミングパターン (Python)
import csv
import json
import sys
writer = sys.stdout
reader = csv.DictReader(open("huge.csv", encoding="utf-8"))
for row in reader:
writer.write(json.dumps(row, ensure_ascii=False) + "\n")
NDJSON で出力。1 行ごとのメモリ消費だけなので入力サイズによらずフラット。gzip -c > out.ndjson.gz で圧縮しながら BigQuery / S3 に流せます。
CI/CD ワークフロー (curl POST と GitHub Actions)
実務でよくある用途。Git で管理している CSV を JSON に変換し、push のたびに API に POST する。
# 変換
python3 csv2json.py < users.csv > users.json
# API に POST
curl -X POST https://api.example.com/users/bulk \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_TOKEN" \
-d @users.json
GitHub Actions:
name: Sync user CSV to API
on:
push:
paths: ["data/users.csv"]
jobs:
sync:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Miller
run: sudo apt-get install -y miller
- name: Convert and upload
env:
API_TOKEN: ${{ secrets.API_TOKEN }}
run: |
mlr --icsv --ojson cat data/users.csv > users.json
curl -fsS -X POST https://api.example.com/users/bulk \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_TOKEN" \
-d @users.json
API のアドホックなテストなら、CSV を CSV to JSON ツール に貼り付けて変換結果をコピーし、Postman / Insomnia / curl --data に貼り付ければ十分。
変換後の JSON をきれいに整形してから送りたい場合は JSON 整形のコツ を参照してください。インデント、キー順序、minify の選択について解説しています。
よくある質問
Excel から出力した CSV の BOM は FormatArc で扱える?
はい。ブラウザツール は UTF-8 BOM を自動検出して除去します。Python の場合は encoding="utf-8-sig"、Node.js の場合は papaparse が透過的に処理します。
NDJSON (JSON Lines) で出力できる?
FormatArc ブラウザツールは現在 JSON 配列を出力します。NDJSON が欲しい場合は Miller (mlr --icsv --ojsonl) または csvkit (csvjson --stream) を使ってください。ログパイプラインや DB バルクインポートはこれが標準です。
ヘッダーなしの CSV を変換するには?
csv.DictReader には fieldnames を明示的に渡します:
reader = csv.DictReader(f, fieldnames=["id", "name", "score"])
PapaParse なら Papa.parse(csv, { header: false }) で配列の配列を取得し、行ごとにオブジェクトに変換します。
数値 ID 列が文字列で出力されてしまう
ほとんどのツールは安全側でデフォルト文字列出力にしています。数値で欲しい場合は型推論を有効化: PapaParse の dynamicTyping: true、Miller の --inumeric、pandas の dtype。ただし 15 桁を超える ID は JavaScript / JSON の倍精度浮動小数点制約で精度落ちすることに注意。
JSON のキーの先頭に  が見える
それは UTF-8 BOM を Latin-1 で表示した状態。Python で encoding="utf-8-sig"、あるいは sed '1s/^\xEF\xBB\xBF//' data.csv で前処理してください。
ブラウザで変換できる最大 CSV サイズは?
実用範囲で 50 MB 程度 (ノート PC のメモリ次第)。ブラウザは元テキストとパース結果の両方をメモリに保持するので、入力サイズの 3〜5 倍のメモリを使います。大規模ファイルは Miller / pandas chunksize / Go プログラムでストリーミング処理してください。
セル内に JSON 値が入っている CSV を変換するには?
セル内に "{""key"":""value""}" のような JSON が入っている場合、文字列としてパースしてから json.loads() で読み直します:
import pandas as pd, json
df = pd.read_csv("data.csv")
df["metadata"] = df["metadata"].apply(json.loads)
df.to_json("data.json", orient="records", force_ascii=False)
列順を JSON 出力でも保持したい
主要ツールはすべて列順を保持します。Python の dict は 3.7 以降挿入順を保持、csv.DictReader はヘッダー順を使用、pandas の to_json(orient="records") は列順を維持。json.dump は sort_keys=True を渡さない限り並べ替えません。
関連ガイド
- CSV とは — 形式の歴史、RFC 4180、よくある方言
- JSON とは — JSON のデータモデルと型
- CSV → Markdown テーブル変換 — 表として読ませたい場合
- JSON → YAML 変換 — 下流が Kubernetes / Docker Compose の場合の次工程
- JSON YAML 変換ツール — 生成した JSON をそのまま貼り付けて、Kubernetes / Docker Compose / OpenAPI 用の YAML をブラウザ内で作成
- JSON 整形のコツ — 変換後の JSON を読みやすく整える
- curl で JSON を整形する — 変換結果を API でテストする際の整形術
まとめ
CSV → JSON 変換は用途別に方法を使い分けるのが現実的です。
- インストール不要・機密データ: FormatArc CSV to JSON — ブラウザ完結、アップロード不要、エンコーディング問題対応
- シェルパイプライン: Miller (
mlr --icsv --ojson) または csvkit (csvjson) - Python アプリ: 標準ライブラリの
csv.DictReader、大規模ファイルや型推論には pandas - Node.js アプリ: PapaParse の
dynamicTyping+ 大規模ファイルはstepコールバック - Go サービス:
encoding/csv+ headers → map ループ
押さえるべき 4 つのポイント: 適切な出力形式 (配列 / NDJSON / Keyed / 列指向 / ネスト) を選ぶ、入力エンコーディング (UTF-8 BOM / Shift-JIS / Latin-1) を合わせる、型推論を有効にするかを判断、100 MB を超えるファイルはストリーミングを使う。