Web ページをそのままコピーして ChatGPT や Claude、Gemini に貼り付けることはできますが、ほぼ毎回 2 つの代償を払っています。トークンの浪費と、回答品質の低下です。コピーした HTML には div のラッパー、class 属性、インラインスクリプト、トラッキング用ピクセルなど、モデルが本文を理解するうえで不要な要素が大量に含まれています。Markdown ならその余分が削ぎ落とされ、構造と本文だけがモデルに届きます。
この記事では Markdown と HTML を LLM 入力としての観点で比較し、実測値で違いを示します。HTML を渡すべき例外的なケースにも触れたうえで、社内 HTML を外部のサーバーに送信せずブラウザ内で変換する手順を紹介します。
まず結論から
LLM への入力には Markdown を選んでください。同等内容の HTML と比べてトークン数は概ね 3 分の 1 から 10 分の 1 ほどに収まり、外部の検証データでは表・リスト・コードブロックの抽出精度も上回ります。HTML を HTML to Markdown に貼り付けて変換し、結果をプロンプトにコピーするだけです。変換処理はブラウザ内で完結し、貼り付けた HTML は FormatArc にも第三者サービスにもアップロードされません。
LLM はフォーマットをどう読むか
LLM はブラウザのようにレンダリングされた HTML を「見て」いるわけではありません。生のソースをトークン列として処理します。角括弧、クラス名、インラインスタイル、それらすべてが、本来コンテンツを置きたいコンテキストウィンドウから容量を奪います。
ここから 2 つの帰結が生まれます。
- ラッパー要素の多い HTML を渡すと、指示文・例示・モデルの応答を入れるスペースが減ります
class="text-base text-gray-700"やdata-*属性、解析タグなどのノイズが、抽出や書き換え対象の本文をモデルが見失う原因になります
Markdown は同じ構造 (見出し・リスト・リンク・コード) を、開閉タグの代わりに 1〜2 文字の記号で表現します。結果として短くなり、しかも LLM が訓練データで頻繁に目にしてきたパターンに近くなります。GitHub の README、ドキュメントサイト、Stack Overflow の投稿、フォーラムのスレッドなど、公開された技術文書の大半は Markdown です。
Markdown が軽い構造的な理由は、タグモデルそのものにあります。ページから実際にコピーする HTML (シリアライズされた DOM や CMS の出力) では、ほとんどのコンテナ要素が開閉ペアのタグ (<p>...</p>、<li>...</li>、<td>...</td>、<div>...</div>) として届くため、マークアップのコストは要素ごとに 2 回 (開くために 1 回、閉じるために 1 回) 支払われます (HTML の仕様上は一部の終了タグを省略できますが、レンダリング済み DOM のシリアライズやテンプレートエンジンは結局それらを出力するので、貼り付けるのはその形です)。ネストするとこれが倍増します。行の中のテーブルセルの中のリストは、入るときに開始タグを、出るときに終了タグを積み重ね、各タグはさらに class、id、style、data-* 属性を持てるため、モデルが必要としない意味を加えないまま文字数だけが増えます。Markdown は同じ構造を、一度だけ置く単独のマーカーで表現します。見出しは #、リスト項目は -、テーブルの列境界は |、段落区切りは空行です。繰り返す閉じトークンも、埋める属性スロットもないので、要素あたりのオーバーヘッドは属性やネストの深さで増えるラッパーペアではなく、小さな定数で済みます。下の実測値が定量化しているのはこの差であり、原因は開閉タグの重複が無いことにあります。
それらの構造自体は、公開された仕様で定義されています。中核となる構文 (見出し・リスト・リンク・コードスパンとフェンスコード・段落) は CommonMark Specification別タブで開きます で標準化され、表・タスクリスト・打ち消し線・自動リンクの拡張は GitHub Flavored Markdown Spec別タブで開きます で定義されています。どちらも安定したバージョン管理された文書であり、これらのモデルが訓練に使う公開コーパス全体で Markdown が一貫している理由の一端でもあります。
各モデルの正確な訓練データ比率は公開されていないので、ここを断定的に語るのは避けます。検証可能なのは、Markdown が公開技術文書で広く使われていること、そして主要モデルベンダーが自社のプロンプト設計ガイドで明示的に Markdown 風の構造を推奨していることです。たとえば Anthropic の Claude プロンプト設計ガイドや Google の Gemini プロンプト設計ガイドは、いずれも見出しと箇条書きでセクションを区切るよう案内しています。
トークン効率の実測比較
公平に比較するため、JSON とは何かを説明する短い技術文書を新たに用意しました。1 つの h2 見出し・2〜3 段落・3 項目の箇条書き・JSON コードブロック・3 列の表で構成した架空のドキュメントを、HTML 版・Markdown 版・Plain text 版の 3 形式で書き起こしています。HTML 版は CMS ページでよく見るラッパーパターン(Tailwind 風クラスと aria 属性)を採用し、Markdown 版は CommonMark に GFM別タブで開きます の表拡張を加えた書式で書き、Plain text 版は HTML からマークアップタグを除去して表をタブ区切り行で表現した形にしました。3 形式の全文と再現スクリプトはリポジトリ内 scripts/benchmarks/markdown-vs-html-for-llms/ にコミットしており、本節末尾でも全文を公開しています。
トークン数は OpenAI 公式の tiktoken別タブで開きます 0.13.0 で実測しました。cl100k_base は GPT-3.5 / GPT-4 系、o200k_base は GPT-4o 系で採用されている tokenizer です。
| 形式 | 文字数 (UTF-8) | バイト数 | cl100k_base トークン | o200k_base トークン |
|---|---|---|---|---|
| HTML (クラスと aria 付き) | 2,911 | 2,911 | 832 | 835 |
| Markdown (GFM) | 1,071 | 1,071 | 243 | 247 |
| Plain text (タグ削除) | 986 | 986 | 213 | 217 |
HTML 比で Markdown はトークン数 -70.8%(cl100k_base)/ -70.4%(o200k_base)、Plain text は -74.4% / -74.0% です。文字数では Markdown -63.2%、Plain text -66.1%。1 トークンあたりの文字数は HTML が 3.50、Markdown が 4.41、Plain text が 4.63 と、HTML が記号トークン(<、>、=、"、属性名)でトークン効率が落ちていることが数値で見て取れます。Claude や Gemini の tokenizer は実装が異なるため絶対値はずれますが、HTML のラッパー税で同じ方向に差が出るのは BPE 系 tokenizer に共通です。
上記はあくまで「この合成サンプル文書」での実測値です。実際の Web ページはこれより遥かに雑然としており、外部の検証データではさらに大きな差が出ています。
- Web2MD のベンチマーク別タブで開きます: 6 種類の代表的なページタイプの平均で 87.5% トークン削減、3,000 語の記事で HTML 約 8,000 トークン → Markdown 約 2,800 トークン (-67%)
- Beam.ai の 2026 年レポート別タブで開きます: クリーンな本文で 68% 削減、実環境の Web ページでは最大 87% 削減
- ReleasePad の分析別タブで開きます: 単純な箇条書きで 10〜20% 削減、ラッパー要素が増えるほど差が拡大
どの数値を信用するにせよ方向は揃っています。HTML はラッパー税を払っており、コンテキスト窓に複数のドキュメントを詰め込みたい局面ほどその税は累積します。
使用したサンプル文書(全文)
HTML 版(2,911 文字 / 832 cl100k トークン)
<section class="prose prose-lg max-w-none">
<h2 class="text-2xl font-semibold mt-8 mb-4" id="what-is-json">What is JSON?</h2>
<p class="text-base text-gray-700 leading-relaxed mb-4">JSON (JavaScript Object Notation) is a lightweight, text-based data format used to exchange structured data between systems. It originated in JavaScript but is now language-independent and supported by virtually every modern programming language.</p>
<p class="text-base text-gray-700 leading-relaxed mb-4">A JSON document is built from a small set of building blocks:</p>
<ul class="list-disc pl-6 mb-4 space-y-1">
<li class="text-base text-gray-700">Objects: unordered collections of key-value pairs wrapped in <code class="bg-gray-100 px-1 rounded">{}</code></li>
<li class="text-base text-gray-700">Arrays: ordered lists of values wrapped in <code class="bg-gray-100 px-1 rounded">[]</code></li>
<li class="text-base text-gray-700">Primitives: strings, numbers, booleans, and <code class="bg-gray-100 px-1 rounded">null</code></li>
</ul>
<p class="text-base text-gray-700 leading-relaxed mb-4">Here is a minimal example representing a single user record:</p>
<pre class="bg-gray-900 text-gray-100 p-4 rounded overflow-x-auto mb-4"><code class="language-json">{
"id": 42,
"name": "Ada Lovelace",
"active": true
}</code></pre>
<p class="text-base text-gray-700 leading-relaxed mb-4">The core value types and their typical use cases are summarized below.</p>
<table class="w-full border-collapse mb-4" aria-label="JSON value types">
<thead>
<tr class="border-b border-gray-300">
<th class="text-left p-2 font-semibold">Type</th>
<th class="text-left p-2 font-semibold">Example</th>
<th class="text-left p-2 font-semibold">Typical use</th>
</tr>
</thead>
<tbody>
<tr class="border-b border-gray-200">
<td class="p-2"><code class="bg-gray-100 px-1 rounded">string</code></td>
<td class="p-2"><code class="bg-gray-100 px-1 rounded">"hello"</code></td>
<td class="p-2">Names, labels, free text</td>
</tr>
<tr class="border-b border-gray-200">
<td class="p-2"><code class="bg-gray-100 px-1 rounded">number</code></td>
<td class="p-2"><code class="bg-gray-100 px-1 rounded">3.14</code></td>
<td class="p-2">IDs, counts, measurements</td>
</tr>
<tr class="border-b border-gray-200">
<td class="p-2"><code class="bg-gray-100 px-1 rounded">boolean</code></td>
<td class="p-2"><code class="bg-gray-100 px-1 rounded">true</code></td>
<td class="p-2">Flags, feature toggles</td>
</tr>
</tbody>
</table>
<p class="text-base text-gray-700 leading-relaxed mb-4">JSON is widely used for REST API payloads, configuration files, and persisting application state because it is easy to read, easy to parse, and supported everywhere.</p>
</section>
Markdown 版 / CommonMark + GFM(1,071 文字 / 243 cl100k トークン)
## What is JSON?
JSON (JavaScript Object Notation) is a lightweight, text-based data format used to exchange structured data between systems. It originated in JavaScript but is now language-independent and supported by virtually every modern programming language.
A JSON document is built from a small set of building blocks:
- Objects: unordered collections of key-value pairs wrapped in `{}`
- Arrays: ordered lists of values wrapped in `[]`
- Primitives: strings, numbers, booleans, and `null`
Here is a minimal example representing a single user record:
```json
{
"id": 42,
"name": "Ada Lovelace",
"active": true
}
```
The core value types and their typical use cases are summarized below.
| Type | Example | Typical use |
| --- | --- | --- |
| string | `"hello"` | Names, labels, free text |
| number | `3.14` | IDs, counts, measurements |
| boolean | `true` | Flags, feature toggles |
JSON is widely used for REST API payloads, configuration files, and persisting application state because it is easy to read, easy to parse, and supported everywhere.
Plain text 版(986 文字 / 213 cl100k トークン)
What is JSON?
JSON (JavaScript Object Notation) is a lightweight, text-based data format used to exchange structured data between systems. It originated in JavaScript but is now language-independent and supported by virtually every modern programming language.
A JSON document is built from a small set of building blocks:
Objects: unordered collections of key-value pairs wrapped in {}
Arrays: ordered lists of values wrapped in []
Primitives: strings, numbers, booleans, and null
Here is a minimal example representing a single user record:
{
"id": 42,
"name": "Ada Lovelace",
"active": true
}
The core value types and their typical use cases are summarized below.
Type Example Typical use
string "hello" Names, labels, free text
number 3.14 IDs, counts, measurements
boolean true Flags, feature toggles
JSON is widely used for REST API payloads, configuration files, and persisting application state because it is easy to read, easy to parse, and supported everywhere.
3 形式の生ファイル・OpenAI tiktoken を使った再現スクリプト(measure.py)・実測結果の JSON は、リポジトリの scripts/benchmarks/markdown-vs-html-for-llms/ にコミットしてあります。python3 -m venv venv && ./venv/bin/pip install tiktoken==0.13.0 && ./venv/bin/python measure.py を実行すれば、本節冒頭の表とまったく同じ数値が出ます。
機密 HTML を外部に送らずに変換する
トークン量と精度の話は他の記事でも語られています。ほとんどの記事がスキップする論点は、変換ステップそのもので HTML がどこを経由するか、です。
オンラインの「HTML to Markdown」変換ツールの多くはバックエンドサーバー上で処理しています。貼り付けると API にポストされ、サーバー側で変換した結果が返ってきます。公開済みの Wikipedia 記事ならそれで構いません。しかし次のようなケースには向きません。
- Confluence や Notion からエクスポートした社内ドキュメント
- 顧客名が含まれる管理画面の HTML ダンプ
- マーケコピー承認前のステージング環境のレスポンスボディ
- 個人情報入りの HTML メール
FormatArc の HTML to Markdown は静的ページです。Markdown 変換はページに同梱された JavaScript の Turndown別タブで開きます ライブラリで実行されます。貼り付けた HTML はブラウザ内でパースされ、ソースを外部に送信するネットワークリクエストは発生しません。確認したければブラウザの DevTools のネットワークタブを開き、識別しやすい文字列を HTML 側に貼って実行ボタンを押し、その文字列を含む外向き通信が無いことをご自身で確かめてください。
「ブラウザ内変換」が指すのは、変換対象の HTML 本文を送信しない、という意味です。ページ自身は CDN から HTTPS で配信されますし、初回訪問時に標準的なアクセス解析が読み込まれる場合はあります。それでも変換するドキュメント本体が外部に出ることはありません。
抽出精度: 表・コード・リスト
トークン数は分かりやすい指標ですが、最終的に役立つかは抽出精度で決まります。
公開ベンチマークでは次のような場面で Markdown が優位とされます。
- 表の抽出: ReleasePad の分析別タブで開きます で広く引用されている GPT 系の評価では、Markdown 表 60.7% vs HTML 表 53.6%。同じ元データに対して 7 ポイントの差です
- コードブロック: Markdown のフェンス記法に言語ヒント (
```python) を付ければ、言語シグナルがそのまま残ります。HTML では<pre><code class="language-python">のようにクラス属性内に埋もれ、モデルがマークアップから掘り出す必要があります - ネストしたリスト: Markdown のインデントは少ないトークンで強い構造シグナルを作れます。HTML の
<ul><li><ul><li>の入れ子はトークンを消費し、ときにモデルが「この子要素がどのリストに属するか」を取り違えます
これだけで Markdown が万能、というわけではありません (次節で HTML が勝つ場面を整理します)。ただし「この記事を要約して」「この項目を抽出して」「この章を書き直して」といった日常的なプロンプトでは、精度面でもトークン面と同じ方向を指しています。
HTML を選ぶべき例外
Markdown が常に正解ではありません。HTML をそのまま貼るほうが妥当な場面が 3 つあります。
意味が属性に乗っているとき
aria-label、role、itemprop、microdata、Open Graph タグなどは Markdown に等価物がありません。アクセシビリティの監査、商品メタデータの抽出、schema.org マークアップの検証などをモデルに依頼する場合、HTML 属性そのものが分析対象です。Markdown コンバータで属性を落としてしまうと、タスクの前提が壊れます。
視覚レイアウトを理由付ける必要があるとき
SVG 図、埋め込みチャート、<iframe> ウィジェット、インタラクティブコンポーネントのカスタムデータ属性などは HTML には残り、Markdown では消えます。Anthropic の Thariq Shihipar が 2026 年 5 月に公開した Using Claude Code: The Unreasonable Effectiveness of HTML別タブで開きます では、人間向けにリッチな出力を生む AI エージェントには HTML の表現力 (スタイル付きレイアウト・インタラクティブ要素・埋め込み SVG) が高いトークンコストを払う価値がある、と主張されています。この主張は入力にも対称的に当てはまり、モデルに分析させたい「視覚」が入力に含まれるなら HTML を渡すべきです。
結果をそのまま HTML として描画する場合
モデルの出力をそのままブラウザでレンダリングする用途なら、Markdown を経由せず HTML のまま投入したほうがツール構成が単純になることがあります。これはどちらかというとパイプライン設計の話で、Markdown は HTML との往復に強いので、決定的な選定理由にはなりません。
実用ワークフロー: HTML から LLM 向け Markdown へ
日常的なケース、つまり「Web ページや HTML メールがあり、マークアップの税を払わずに LLM に内容を渡したい」場合のワークフローを示します。データを手元に留める前提で組んでいます。
ステップ 1: HTML を取得する
Chrome や Firefox で対象ページを右クリックして「ページのソースを表示」を選ぶか、DevTools の Elements パネルから <article> や <main> の outerHTML をコピーします。HTML メールならメールクライアントの「ソースを表示」から取得します。
本文だけが必要なら、その部分木だけをコピーしてください。ナビゲーション・サイドバー・フッターをこの段階で外しておくと、後段のあらゆる工夫よりも大きくトークン予算を節約できます。
ステップ 2: ブラウザで変換する
HTML to Markdown に貼り付けて実行ボタンを押すと、右側に Markdown が出ます。
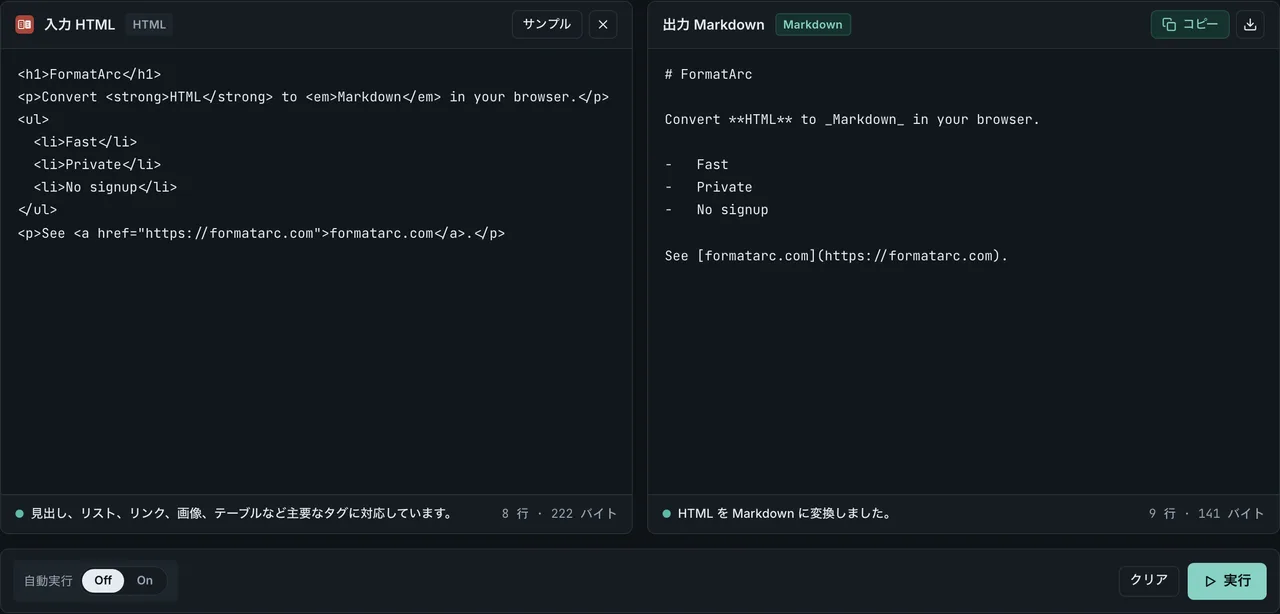
変換そのものの詳細 (表・画像パス・colspan の取り扱い) は HTML to Markdown 変換ガイド に整理しています。モデルが Markdown で返してきた回答を HTML に戻したい逆方向のニーズには Markdown to HTML が同じくローカルで処理できます。
ステップ 3: 貼り付ける前に整える
変換後の Markdown を眺めて、残骸を削ります。
- 冒頭にリスト化されたナビゲーションリンク
- 段落の形で残ったクッキー同意バナー
- フッターの著作権表記
2 分の手作業でのトリミングが、後続のどんな自動化よりも多くのコンテキストを取り戻します。
ステップ 4: 整えた Markdown でプロンプトを書く
抽出系タスクで使い回しやすい雛形は次のとおりです。
以下はドキュメントページの Markdown です。
タスク: <1 文で書く>
制約: <出力形式や長さの指定>
---
<整えた Markdown を貼り付け>
Markdown の見出しは「Syntax の節では…」のようにモデルが具体的に参照しやすい錨になり、回答の具体性が上がります。
LLM 入力用に変換する際の落とし穴
頻出する 5 点に注意してください。
- コードブロックの言語ヒントが消える。
<pre><code class="language-python">は```pythonに変換されるべきですが、ヒントを落とすコンバータもあります。落ちるとモデルが言語を推測する必要が生じます colspan/rowspanを含む表が崩れる。GFM のパイプ表は矩形のみなので結合セルは潰れます。データ表なら一度 CSV to Markdown を経由する選択肢もあります。変換手順は CSV を Markdown テーブルに変換する方法、配置やエスケープの記法は Markdown 表の書き方 と GFM テーブル チートシート を参照- 生の HTML が Markdown 中に残る。CommonMark も GFM もインライン HTML を許容します。
<span class="text-red">important</span>がモデルに渡る Markdown に残ると、結局ラッパー税のバケツに戻ります。可能なら純粋な Markdown だけを生成するコンバータを選び、本当に必要な構造 (数式・複雑な表) でのみ HTML を残してください - 相対パスの画像とリンク。
<img src="/images/foo.png">はになりますが、LLM はそのパスを取得できません。絶対 URL に書き換えるか、プロンプトで「画像は取得不可」と明記してください - CommonMark と GFM の差。表・タスクリスト・打ち消し線・自動リンクは GFM の拡張です。下流のレンダラが厳格な CommonMark のみだと、これらは表示されません。境界は CommonMark と GFM の違い を参照してください
フォーマット選定の早見表
| 形式 | LLM 入力としての推奨用途 | トークンコスト | 強み | 弱み |
|---|---|---|---|---|
| Markdown | 大半の入力 (ドキュメント、記事、README、チャットログ) のデフォルト | 低 | 訓練データに近い構造シグナル、表・リスト・コードが残る | 属性意味やインラインスタイルを失う |
| Plain text | 純粋なテキスト抽出、OCR 的タスク | 最小 | 最も軽い | 構造が消える、リストや表に不向き |
| HTML | アクセシビリティ監査、schema.org / microdata、視覚レイアウトの推論 | 高 | 属性・意味・埋め込みメディアを保持 | ラッパー税、ノイズによる注意散漫 |
| JSON | 構造化レコード、API レスポンス、関数呼び出し payload | 中 | スキーマが明示的でキーをパターン一致しやすい | 散文には冗長、引用符オーバーヘッド |
| XML | Claude でのプロンプトセクション区切り (Anthropic 推奨) | 中 | プロンプト各部の境界が明確 | 冗長で、本文には CommonMark で十分 |
「この記事を要約」「この項目を抽出」「平易に書き直す」といった日常プロンプトでは Markdown を既定値にして問題ありません。
よくある質問
ChatGPT のコンテキストには Markdown と Plain text のどちらが良いですか
ソースに何らかの構造 (見出し・リスト・表・コード) があるなら Markdown を選んでください。完全にフラットな散文だけなら Plain text のほうが小さく済みます。Plain text は最安ですが、長い文脈をモデルが辿るのに必要な構造シグナルを捨てる選択でもあります。
Claude は HTML より Markdown を理解しやすいですか
Claude は両方とも扱えます。Anthropic のプロンプト設計ガイドは Markdown 風の見出し・リストでセクションを区切るよう推奨しつつ、プロンプト各部の境界を明示するために XML タグ (<instructions>、<context>) の併用も勧めています。本文のトークン効率では Markdown が有利で、本文の外側の足場として XML を併用するのが現実解です。
構造化コンテキストには JSON や XML が良くないですか
データが本来的に表形式 / レコード形式 (API レスポンス、設定) なら JSON が向きます。プロンプト内のセクション境界を明示したい場合は XML が向きます (Anthropic のドキュメントがこのスタイルです)。散文ではどちらも Markdown のトークンコストには勝てません。
URL を直接 LLM 向け Markdown に変換できますか
静的ページから任意の URL を完全クライアントサイドで取得する方法はありません (CORS で弾かれます)。一旦ページをローカル保存 (Cmd/Ctrl-S) するか、DevTools からソースをコピーし、HTML を HTML to Markdown に貼り付けてください。変換自体はブラウザ内で完結します。
FormatArc の変換は本当にブラウザ内だけで動きますか
変換ステップに関しては「はい」です。貼り付けた HTML はページに同梱された Turndown別タブで開きます JavaScript ライブラリでパースされ、ソースを含む外向きリクエストは送信されません。ページ自体は CDN から HTTPS で配信され、初回訪問時に標準的なアクセス解析が走る場合はありますが、貼り付けた HTML はそれらの通信には含まれません。
まとめ
LLM のコンテキストには Markdown が HTML より有利です。トークンが少なく済み、モデルが足場ではなく本文に集中できます。具体的な比率は元ページに依存しますが、公開ベンチマークが示す方向は一致しています。
ソース HTML が機密 (社内ドキュメント、顧客データ、未公開ドラフト) なら、変換ステップ自体が重要です。HTML to Markdown はブラウザ内で動作するため、ソースが第三者のサーバーに到達しません。
逆方向の変換は Markdown to HTML と Markdown HTML 変換ガイド を、変換後 Markdown の表まわりの具体的な書き方は Markdown 表の書き方 を参照してください。