TL;DR — escolha um método em 10 segundos
- Precisa agora, sem instalar nada → FormatArc CSV para JSON (roda no navegador, sem upload, lida com UTF-8, Windows-1252, Latin-1 e outras codificações, vírgulas entre aspas, quebras de linha dentro de campos)
- Scripts de shell / one-liners →
csvjson data.csv(csvkit) oumlr --icsv --ojson cat data.csv(Miller) - Dentro de um app Python →
csv.DictReader(biblioteca padrão, zero dependências) oupandas.read_csvpara arquivos grandes - Dentro de um app Node.js → PapaParse com
{ header: true, dynamicTyping: true } - Dentro de um serviço Go →
encoding/csvmais um pequeno loop headers→map - Arquivos grandes (1M+ linhas) → faça streaming linha a linha com
csv.DictReader+ JSON Lines, nunca apliquejson.dumpna lista inteira
| Método | Configuração | Streaming de arquivos grandes | Inferência de tipos | Saída NDJSON |
|---|---|---|---|---|
| FormatArc navegador | Nenhuma | Até ~50 MB de memória do navegador | Sim (configurável) | Não (use a CLI) |
Python csv.DictReader | biblioteca padrão | Sim (com loop de escrita manual) | Não (tudo string) | Sim |
pandas read_csv | pip install pandas | Em blocos via chunksize= | Sim (dtype inferido) | Sim (lines=True) |
Miller (mlr) | brew install miller | Sim (streaming) | Sim (--inumeric) | Sim (--ojsonl) |
csvkit (csvjson) | pip install csvkit | Não (carrega tudo) | Sim (--no-inference para desabilitar) | Não |
| PapaParse (Node) | npm install papaparse | Sim (callback step) | Sim (dynamicTyping) | Sim (manual) |
Go encoding/csv | biblioteca padrão | Sim (loop Read) | Não (cast manual) | Sim (manual) |
Este guia cobre cada método com código funcional, e depois as quatro coisas que mais confundem as pessoas: formato de saída, codificação, inferência de tipos e desempenho com arquivos grandes.
Revisão do formato CSV (RFC 4180)
CSV significa Comma-Separated Values (valores separados por vírgula). O formato é especificado de maneira informal pela RFC 4180Abre em uma nova aba, mas na prática você vai encontrar muitas variantes. Um arquivo CSV típico:
name,email,department,start_date
Alice Johnson,alice@example.com,Engineering,2024-01-15
Bob Smith,bob@example.com,Marketing,2023-06-01
Carol Williams,carol@example.com,Engineering,2024-03-10
A primeira linha geralmente é o cabeçalho. Cada linha seguinte é um registro. Os campos são separados por vírgulas, mas o formato tem peculiaridades bem conhecidas:
- Campos que contêm vírgulas precisam ficar entre aspas duplas:
"Smith, John" - Campos que contêm aspas duplas precisam escapá-las dobrando-as:
"She said ""hello""" - Quebras de linha dentro de campos entre aspas são válidas (e frequentemente causam problemas em parsers ingênuos)
- Não há padrão para codificação — você pode receber UTF-8, Windows-1252 (padrão do Excel Windows em
pt-BR/pt-PT), Latin-1, UTF-8 com BOM (padrão de "CSV UTF-8" no Excel moderno) ou codificações herdadas asiáticas (Shift-JIS, EUC-KR, GB2312) dependendo da origem - O próprio caractere separador não é padronizado: TSV usa tabs, o Excel europeu usa
;, alguns conjuntos de dados científicos usam|
Para mais contexto sobre o formato e sua história, veja O que é CSV.
Por que converter CSV para JSON?
Vários motivos práticos aparecem com frequência:
- APIs REST aceitam corpos de requisição em JSON, não em CSV. Se você tem dados em uma planilha que precisa enviar via POST para uma API, primeiro precisa convertê-los.
- Frameworks de frontend (React, Vue, Svelte) trabalham naturalmente com arrays e objetos JSON. Fazer parse de CSV no navegador é possível, mas adiciona uma dependência extra.
- Preservação de tipos: em CSV tudo é string. Em JSON você consegue distinguir entre números, booleanos, strings e null.
- Bancos de dados NoSQL como MongoDB, CouchDB e DynamoDB importam JSON Lines (NDJSON) diretamente via carregadores em massa.
- Pipelines de dados e ferramentas de ETL (Apache Airflow, Prefect, Mage, dbt) cada vez mais esperam JSON ou NDJSON como formato de intercâmbio entre etapas.
- Contexto para LLMs: alimentar dados tabulares para um LLM como objetos JSON é mais confiável do que CSV — o modelo identifica as chaves de forma consistente. Veja Markdown vs HTML para LLMs para o guia de escolha de formato.
Entender ambos os formatos ajuda você a tomar decisões embasadas. Veja O que é JSON para um olhar aprofundado sobre a estrutura e as capacidades do JSON.
5 formatos de saída que você pode querer
A maioria dos conversores de CSV para JSON gera exatamente um formato: um array de objetos com os valores do cabeçalho como chaves. Isso funciona para metade dos casos de uso. Para a outra metade, você precisa de um formato diferente. Aqui está o mesmo CSV nos cinco formatos para você escolher o certo.
Entrada:
id,name,score
1,Alice,95
2,Bob,87
3,Carol,92
Formato 1: Array de objetos (padrão na maioria das ferramentas)
[
{ "id": 1, "name": "Alice", "score": 95 },
{ "id": 2, "name": "Bob", "score": 87 },
{ "id": 3, "name": "Carol", "score": 92 }
]
Melhor para: APIs REST, renderização no frontend, troca genérica de dados.
Formato 2: Objeto indexado (coluna como chave primária)
{
"1": { "name": "Alice", "score": 95 },
"2": { "name": "Bob", "score": 87 },
"3": { "name": "Carol", "score": 92 }
}
Melhor para: tabelas de consulta, acesso por dicionário usando o ID. Produza com Python:
import csv, json, sys
rows = list(csv.DictReader(sys.stdin))
result = {row["id"]: {k: v for k, v in row.items() if k != "id"} for row in rows}
json.dump(result, sys.stdout, indent=2)
Formato 3: JSON Lines / NDJSON (JSON delimitado por quebra de linha)
{"id":1,"name":"Alice","score":95}
{"id":2,"name":"Bob","score":87}
{"id":3,"name":"Carol","score":92}
Melhor para: ingestão em streaming (BigQuery, Snowflake COPY INTO, MongoDB mongoimport --type=json, pipelines de logs, produtores Kafka). Cada linha pode ser parseada de forma independente, então você consegue processar um arquivo de 10 GB linha a linha sem carregá-lo todo na memória.
Produza com Miller: mlr --icsv --ojsonl cat data.csv. Ou com jq: jq -c '.[]' array.json > lines.ndjson.
Formato 4: Orientado a colunas (arrays paralelos)
{
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Carol"],
"score": [95, 87, 92]
}
Melhor para: ciência de dados (corresponde ao layout interno do Apache Arrow / pandas), pipelines de GPU, bancos de dados colunares. Produza com pandas: df.to_dict(orient="list").
Formato 5: Aninhado via cabeçalhos delimitados por barra
CSV de entrada com nomes de cabeçalho delimitados por barra:
id,name,address/city,address/zip
1,Alice,Tokyo,150-0001
2,Bob,Osaka,530-0001
Saída (aninhada):
[
{ "id": 1, "name": "Alice", "address": { "city": "Tokyo", "zip": "150-0001" } },
{ "id": 2, "name": "Bob", "address": { "city": "Osaka", "zip": "530-0001" } }
]
Melhor para: produzir corpos de requisição de API que esperam estruturas aninhadas. A maioria das ferramentas exige pós-processamento (veja Saída JSON aninhada abaixo).
Método 1: ferramenta de navegador FormatArc (sem upload)
Se você precisa converter um arquivo CSV agora mesmo sem instalar nada, a ferramenta CSV para JSON é o caminho mais rápido. Ela roda inteiramente no seu navegador — seus dados nunca saem da sua máquina.
- Abra CSV para JSON.
- Cole seu CSV no painel da esquerda.
- Clique em Converter. A saída JSON aparece no painel da direita.
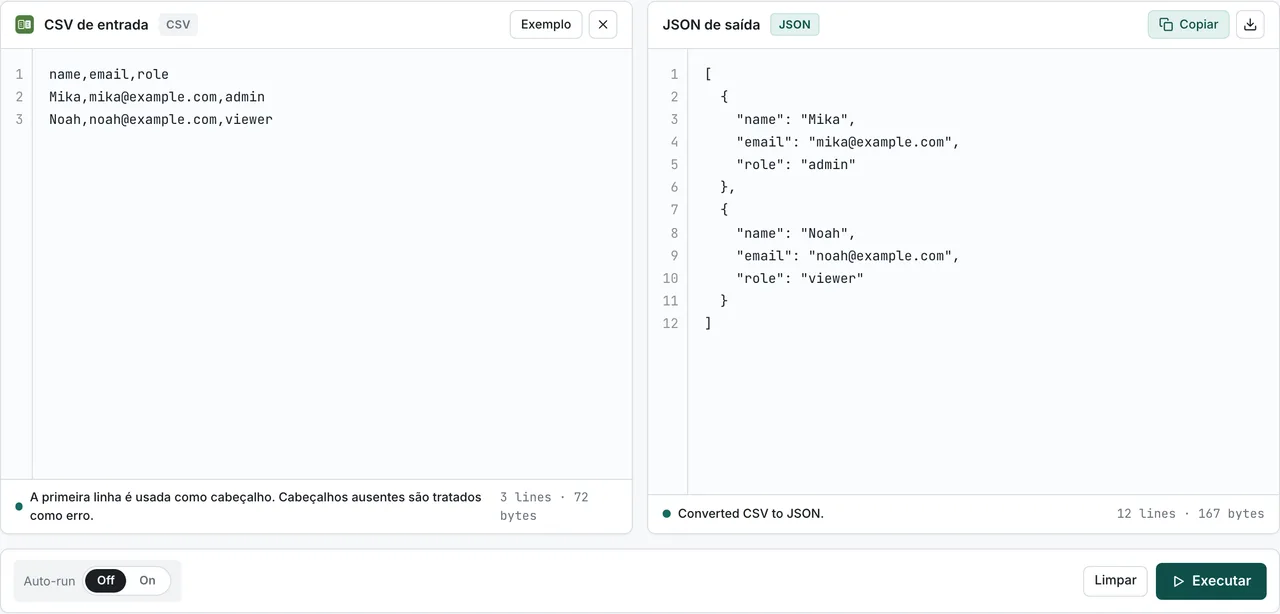
A ferramenta lida com casos de borda que derrubam conversores mais simples: campos entre aspas com vírgulas internas, campos com quebras de linha, campos vazios (convertidos em strings vazias) e conjuntos de dados grandes, de até cerca de 50 MB dependendo da memória do navegador.
A conversão no navegador importa quando o CSV contém dados sensíveis: registros de clientes, tabelas salariais, chaves de API exportadas de um cofre, números financeiros internos. Tudo o que você cola fica na aba do navegador. Não há etapa de upload nem processamento no servidor.
Método 2: Python — csv.DictReader e pandas
O Python já vem com csv e json na biblioteca padrão, então nenhum pacote de terceiros é necessário para a conversão básica:
import csv
import json
import sys
reader = csv.DictReader(sys.stdin)
rows = list(reader)
json.dump(rows, sys.stdout, indent=2, ensure_ascii=False)
Salve como csv2json.py e execute:
python3 csv2json.py < data.csv > data.json
O csv.DictReader usa a primeira linha como cabeçalho automaticamente. Cada linha vira um dict, e a lista de dicts é mapeada para um array JSON de objetos. ensure_ascii=False é importante se o seu CSV contém caracteres não-ASCII (japonês, latim acentuado, emoji) — sem isso, esses caracteres são escapados como sequências あ.
Python com pandas (arquivos grandes e inferência de tipos)
import pandas as pd
df = pd.read_csv("data.csv", encoding="utf-8")
df.to_json("data.json", orient="records", indent=2, force_ascii=False)
orient="records" produz um array de objetos. Outros orients úteis: "index" (objeto indexado), "columns" (orientado a colunas), "values" (array de arrays).
Para arquivos que não cabem na memória, use chunksize para fazer streaming:
import pandas as pd
with open("output.ndjson", "w") as out:
for chunk in pd.read_csv("huge.csv", chunksize=10000):
chunk.to_json(out, orient="records", lines=True, force_ascii=False)
out.write("\n")
Isso produz saída NDJSON e nunca mantém mais de 10.000 linhas na memória de uma vez.
Método 3: Node.js — PapaParse
A biblioteca papaparse é o padrão de fato para parse de CSV em JavaScript. É também o que o FormatArc usa internamente na ferramenta de navegador.
const Papa = require("papaparse");
const fs = require("fs");
const csv = fs.readFileSync("data.csv", "utf8");
const result = Papa.parse(csv, {
header: true,
dynamicTyping: true, // "42" → 42, "true" → true
skipEmptyLines: true,
});
fs.writeFileSync("data.json", JSON.stringify(result.data, null, 2));
Para arquivos grandes, o PapaParse oferece streaming com um callback step:
const fs = require("fs");
const Papa = require("papaparse");
const stream = fs.createReadStream("huge.csv");
const out = fs.createWriteStream("huge.ndjson");
Papa.parse(stream, {
header: true,
dynamicTyping: true,
step: (row) => out.write(JSON.stringify(row.data) + "\n"),
complete: () => out.end(),
});
Cada linha é gravada em disco imediatamente, então o uso de memória permanece estável mesmo em arquivos de vários gigabytes.
Método 4: Go — encoding/csv
package main
import (
"encoding/csv"
"encoding/json"
"fmt"
"os"
)
func main() {
f, _ := os.Open("data.csv")
defer f.Close()
reader := csv.NewReader(f)
records, _ := reader.ReadAll()
headers := records[0]
result := make([]map[string]string, 0, len(records)-1)
for _, row := range records[1:] {
obj := make(map[string]string, len(headers))
for i, val := range row {
obj[headers[i]] = val
}
result = append(result, obj)
}
out, _ := json.MarshalIndent(result, "", " ")
fmt.Println(string(out))
}
O encoding/csv do Go trata cada campo como string — não há inferência de tipos embutida. Se você precisa de saída tipada, faça o parse dos valores manualmente (strconv.Atoi, strconv.ParseFloat, strconv.ParseBool).
Para fazer streaming de arquivos grandes, substitua ReadAll() por um loop for chamando Read() por linha e codifique cada linha como NDJSON via json.Marshal.
Método 5: Miller e csvkit (one-liners)
Para scripts de shell e trabalho pontual, duas ferramentas entregam a conversão de CSV para JSON em um único comando.
Miller (mlr)
O Miller é um processador de dados em streaming — pense no awk para dados estruturados:
# Array de objetos
mlr --icsv --ojson cat data.csv > data.json
# NDJSON (seguro para streaming)
mlr --icsv --ojsonl cat data.csv > data.ndjson
# Filtra e converte em uma única passagem
mlr --icsv --ojson filter '$score > 90' data.csv
# Adiciona uma coluna calculada durante a conversão
mlr --icsv --ojson put '$grade = $score >= 90 ? "A" : "B"' data.csv
Instalação: brew install miller (macOS) ou apt install miller (Debian/Ubuntu).
csvkit (csvjson)
O csvkit é um conjunto de ferramentas CSV em Python:
pip install csvkit
csvjson data.csv > data.json
Opções úteis:
--indent 2— saída formatada--no-inference— mantém todos os valores como strings (não faz cast automático de números)--stream— emite NDJSON em vez de um array--locale ja_JP.UTF-8— para parse de números sensível ao locale
csvjson --stream é o caminho mais simples para NDJSON sem escrever código.
Saída JSON aninhada via cabeçalhos delimitados por barra
A maioria dos conversores produz objetos planos. Se o consumidor a jusante (API REST, schema do Mongo, resolver GraphQL) espera objetos aninhados, você precisa de uma etapa de pós-processamento.
Uma convenção comum é codificar o aninhamento no cabeçalho com um separador como / ou .:
id,name,address/city,address/zip,address/country
1,Alice,Tokyo,150-0001,JP
2,Bob,Osaka,530-0001,JP
Converta e aninhe com Python:
import csv, json, sys
def nest(row, sep="/"):
result = {}
for key, val in row.items():
parts = key.split(sep)
cursor = result
for part in parts[:-1]:
cursor = cursor.setdefault(part, {})
cursor[parts[-1]] = val
return result
reader = csv.DictReader(sys.stdin)
rows = [nest(r) for r in reader]
json.dump(rows, sys.stdout, indent=2, ensure_ascii=False)
Saída:
[
{ "id": "1", "name": "Alice", "address": { "city": "Tokyo", "zip": "150-0001", "country": "JP" } },
{ "id": "2", "name": "Bob", "address": { "city": "Osaka", "zip": "530-0001", "country": "JP" } }
]
Para notação com ponto (address.city em vez de address/city), troque o separador. O site convertcsv.com popularizou essa convenção com / e suporta até 10 níveis de aninhamento.
Lidando com codificação (BOM / Windows-1252 / Latin-1 / vírgulas entre aspas / quebras de linha internas)
Incompatibilidades de codificação são a causa isolada mais comum de saída CSV para JSON corrompida. Em países lusófonos o cenário mais comum é Windows-1252 (padrão do Excel no Windows em locales pt-BR e pt-PT) ou UTF-8 com BOM (padrão de "CSV UTF-8" no Excel moderno).
UTF-8 com BOM
O Excel no Windows salva "CSV UTF-8" com um Byte Order Mark (BOM) — três bytes (EF BB BF) no início do arquivo. A maioria dos parsers JSON não remove o BOM, então a primeira chave da saída acaba ficando como name em vez de name.
Remova com Python:
with open("data.csv", encoding="utf-8-sig") as f: # -sig remove o BOM
reader = csv.DictReader(f)
Remova com Miller: mlr --icsv --ojson cat <(sed '1s/^\xEF\xBB\xBF//' data.csv).
Windows-1252 / Latin-1 (padrão do Excel em pt-BR e pt-PT)
O Excel no Windows salva por padrão em Windows-1252 (uma superserie do Latin-1 / ISO-8859-1) quando o usuário escolhe "CSV" no diálogo "Salvar como" em locales pt-BR, pt-PT, es-ES, es-MX e afins. Se o seu CSV contém ã, á, ç, ê, € e você vê mojibake (ã, ç, €) ao fazer parse como UTF-8, quase sempre é Windows-1252:
with open("data.csv", encoding="cp1252") as f: # ou "latin-1" se não houver €/™/œ
reader = csv.DictReader(f)
Conversão de uma etapa no shell: iconv -f CP1252 -t UTF-8 data.csv > data.utf8.csv.
Na ferramenta de navegador do FormatArc, cole texto UTF-8 diretamente. Para arquivos Windows-1252, converta para UTF-8 antes com iconv ou abra o arquivo no seu editor e use "Salvar como" → codificação "UTF-8".
Windows-1252 vs Latin-1: Windows-1252 adiciona 27 caracteres (€, curly quotes, œ, …) no intervalo 0x80–0x9F que o Latin-1 puro reserva para caracteres de controle. Se o texto contém € ou aspas tipográficas e Latin-1 falha, tente Windows-1252.
Outras codificações herdadas: Shift-JIS, EUC-KR, GB2312
Se você recebe CSV de parceiros no Japão, Coreia ou China, verá codificações herdadas específicas da região:
- Shift-JIS — padrão do Excel japonês antes de "CSV UTF-8":
iconv -f SHIFT-JIS -t UTF-8ouencoding="shift-jis"no Python - EUC-KR — coreano:
iconv -f EUC-KR -t UTF-8ouencoding="euc-kr" - GB2312 / GBK / GB18030 — chinês simplificado:
encoding="gb18030"(superserie que cobre os três)
Em todos os casos: converta primeiro para UTF-8, depois parse. Não misture codificações no mesmo pipeline.
Vírgulas entre aspas e quebras de linha internas
Campos que contêm o caractere delimitador precisam estar entre aspas:
id,description
1,"Hello, world"
2,"Multi-line
description here"
Um parser ingênuo divide a cada vírgula e quebra na segunda linha. Use um parser CSV de verdade (DictReader, PapaParse, Miller, csvkit) — todos eles lidam corretamente com aspas e quebras de linha internas. Um string.split(",") improvisado não lida.
Delimitadores diferentes de vírgula (;, tabs, barras verticais)
O Excel europeu costuma usar ;. Especifique o delimitador explicitamente:
reader = csv.DictReader(f, delimiter=";")
mlr --csv --ifs ";" --ojson cat data.csv
Papa.parse(csv, { header: true, delimiter: ";" });
Para TSV (separado por tab): use delimiter="\t" ou --itsv no Miller.
Inferência de tipos (parse de números / booleanos / nulls)
O CSV armazena tudo como texto. Se a sua saída JSON preserva os tipos depende da ferramenta.
| Ferramenta | Comportamento padrão | Como habilitar a inferência |
|---|---|---|
csv.DictReader (biblioteca padrão Python) | Tudo string | Cast manual |
pandas read_csv | Inferido por coluna | Ligado por padrão; desabilite com dtype=str |
| PapaParse (Node) | Tudo string | { dynamicTyping: true } |
Miller (mlr) | Tudo string | flag --inumeric |
csvkit (csvjson) | Inferido | Desabilite com --no-inference |
| FormatArc navegador | Tudo string (previsível para ida e volta) | n/d |
Se você habilitar a inferência, fique atento a surpresas:
"007"vira7(perda dos zeros à esquerda — ruim para números de telefone, CEPs, ISBNs)"NaN"e"Infinity"podem virar floats"true"/"false"/"yes"/"no"podem virar booleanos (o PapaParse só tratatrue/false, o Miller é mais rigoroso)- A string vazia
""pode virarnull,""ou ser omitida completamente, dependendo da ferramenta - Campos de ID que parecem numéricos são forçados a números, perdendo precisão para IDs com mais de 15 dígitos (o
Number.MAX_SAFE_INTEGERdo JavaScript é2^53 - 1)
Padrão seguro: mantenha tudo como string e faça o cast no código da sua aplicação, onde o schema é conhecido. A inferência automática é conveniente para análise, mas insegura para pipelines de dados em produção.
Desempenho e arquivos grandes
Para arquivos com menos de 10.000 linhas, qualquer método funciona. As diferenças aparecem em escala.
| Tamanho do arquivo | Método recomendado | Por quê |
|---|---|---|
| Menos de 10 MB | Ferramenta de navegador, csvkit, pandas | Todos cabem na memória confortavelmente |
| 10–500 MB | pandas chunksize, Miller, streaming do PapaParse, Go | Faça streaming linha a linha, nunca carregue o arquivo inteiro |
| 500 MB+ | Miller, Go, Python csv.DictReader + saída NDJSON | É necessário streaming com memória constante |
Throughput medido (Apple M5 Pro / 64 GB / macOS 26.5, CSV de 5 colunas × 1.000.000 de linhas, single thread; reproduza com scripts/benchmarks/csv-to-json-throughput/ no repositório):
- Python
csv.DictReader+json.dump(Python 3.14.6): ~232.000 linhas/s - pandas
read_csv+to_json(pandas 3.0.3): ~1.113.000 linhas/s - Miller
mlr --c2j(Miller 6.19.0): ~1.960.000 linhas/s (mediana de 5 execuções aquecidas; a primeira execução em frio cai para ~990.000 linhas/s por causa do cache de arquivos) - Go
encoding/csv+encoding/json(Go 1.26.4): ~2.058.000 linhas/s - Streaming do PapaParse (papaparse 5.5.2 / Node 26.3.1): ~1.626.000 linhas/s
- FormatArc no navegador: mesmo motor PapaParse 5.5, mas limitado pela responsividade da thread principal e pela memória da página, de modo que o teto no navegador fica muito abaixo dos números do CLI; confortável em dezenas de MB / centenas de milhares de linhas
Esses números dependem fortemente do hardware, do SO e da versão de cada ferramenta. Em um notebook Intel de 2021, com pandas 2.x ou Miller 5.x, o throughput costuma ser menos da metade — re-meça na sua própria máquina antes de tomar uma decisão.
Para dados na escala de terabytes, nenhuma dessas é a ferramenta certa — use Apache Spark, DuckDB (COPY data FROM 'data.csv' (FORMAT CSV) e depois COPY (SELECT * FROM data) TO 'out.ndjson' (FORMAT JSON, ARRAY false)) ou o Apache Arrow diretamente.
Padrão de streaming para arquivos arbitrariamente grandes (Python)
import csv
import json
import sys
writer = sys.stdout
reader = csv.DictReader(open("huge.csv", encoding="utf-8"))
for row in reader:
writer.write(json.dumps(row, ensure_ascii=False) + "\n")
Isso emite NDJSON. Cada linha usa uma quantidade fixa de memória, independentemente do tamanho da entrada. Encaminhe diretamente para o BigQuery, o S3 ou para gzip -c > out.ndjson.gz.
Fluxo de CI/CD (curl POST e GitHub Actions)
Um caso de uso comum em produção: converter um CSV mantido no Git para JSON e enviá-lo via POST para uma API a cada push.
# Converte
python3 csv2json.py < users.csv > users.json
# POST para uma API
curl -X POST https://api.example.com/users/bulk \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_TOKEN" \
-d @users.json
Exemplo com GitHub Actions:
name: Sync user CSV to API
on:
push:
paths: ["data/users.csv"]
jobs:
sync:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Miller
run: sudo apt-get install -y miller
- name: Convert and upload
env:
API_TOKEN: ${{ secrets.API_TOKEN }}
run: |
mlr --icsv --ojson cat data/users.csv > users.json
curl -fsS -X POST https://api.example.com/users/bulk \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_TOKEN" \
-d @users.json
Para testes pontuais de API, cole o CSV na ferramenta CSV para JSON, copie a saída e cole no Postman, no Insomnia ou no curl --data.
Se você também precisa formatar o JSON resultante antes de enviá-lo, veja Dicas de Formatação de JSON — escolhas de indentação, ordenação de chaves e minificação que mantêm os payloads de API revisáveis.
Perguntas frequentes
O Excel exporta CSV — o FormatArc lida com o BOM?
Sim. A ferramenta de navegador detecta e remove o BOM UTF-8 automaticamente. No Python, use encoding="utf-8-sig". No Node.js, a biblioteca papaparse lida com o BOM de forma transparente.
Consigo obter saída em NDJSON (JSON Lines)?
A ferramenta de navegador do FormatArc atualmente emite um array JSON. Para NDJSON, use o Miller (mlr --icsv --ojsonl) ou o csvkit (csvjson --stream). Essas são as ferramentas padrão para pipelines de logs e importações em massa em bancos de dados.
Como converto um CSV sem cabeçalho?
Para o csv.DictReader, passe fieldnames=["col1", "col2", ...] explicitamente:
reader = csv.DictReader(f, fieldnames=["id", "name", "score"])
Para o PapaParse: Papa.parse(csv, { header: false }) retorna um array de arrays. Depois, mapeie cada linha para um objeto você mesmo.
Por que meus IDs numéricos estão saindo como strings?
A maioria das ferramentas usa saída em string por padrão, por segurança. Para obter números, habilite a inferência de tipos: dynamicTyping: true (PapaParse), --inumeric (Miller) ou dtype no pandas. Atenção: IDs com mais de 15 dígitos perdem precisão em JavaScript / JSON por causa dos limites do float de precisão dupla.
Por que vejo  no início das minhas chaves JSON?
Esse é o BOM UTF-8 exibido como caracteres Latin-1. Remova-o lendo o arquivo com encoding="utf-8-sig" (Python) ou pré-processando com sed '1s/^\xEF\xBB\xBF//' data.csv.
Qual é o maior arquivo CSV que consigo converter no navegador?
Na prática, cerca de 50 MB em um laptop comum. Os navegadores mantêm o texto completo e o resultado parseado na memória, além da memória de trabalho do parser. Para arquivos maiores, use o Miller, o pandas com chunksize ou um programa em Go — todos eles fazem streaming e não têm limite superior além do espaço em disco.
Como converto um CSV com valores JSON aninhados dentro de uma célula?
Se uma célula CSV contém JSON como "{""key"":""value""}", faça o parse dele como string primeiro e depois aplique json.loads() ao resultado. Com pandas:
import pandas as pd, json
df = pd.read_csv("data.csv")
df["metadata"] = df["metadata"].apply(json.loads)
df.to_json("data.json", orient="records", force_ascii=False)
Consigo preservar a ordem das colunas na saída JSON?
Sim, em todas as ferramentas modernas listadas aqui. Os dicts do Python preservam a ordem de inserção desde a versão 3.7, o csv.DictReader usa a ordem da linha de cabeçalho e o pandas to_json(orient="records") respeita a ordem das colunas. O json.dump não reordena as chaves a menos que você passe sort_keys=True.
Guias relacionados
- O que é CSV — história do formato, RFC 4180 e dialetos comuns
- O que é JSON — o modelo de dados e os tipos do JSON
- Conversão de CSV para tabela Markdown — quando você quer uma tabela legível em vez disso
- Conversão de JSON para YAML — próximo passo se o seu consumidor a jusante for Kubernetes ou Docker Compose
- Conversor de JSON para YAML — cole o JSON que você acabou de gerar para produzir YAML de Kubernetes, Docker Compose ou OpenAPI no navegador
- Dicas de Formatação de JSON — produza JSON revisável após a conversão
- curl JSON pretty print — testando a saída convertida contra APIs
Resumo
A conversão de CSV para JSON é uma tarefa rotineira com um método para cada situação:
- Sem instalação, dados sensíveis: FormatArc CSV para JSON — roda no navegador, sem upload, lida com peculiaridades de codificação.
- Pipelines de shell: Miller (
mlr --icsv --ojson) ou csvkit (csvjson). - Aplicações Python:
csv.DictReaderpara a biblioteca padrão; pandas para arquivos grandes e inferência de tipos. - Aplicações Node.js: PapaParse com
dynamicTypinge o callback de streamingsteppara arquivos grandes. - Serviços Go:
encoding/csvmais um pequeno loop headers→map.
As quatro coisas que você precisa acertar: escolher o formato de saída certo (array vs NDJSON vs indexado vs coluna vs aninhado), corresponder à codificação de entrada (UTF-8 com BOM, Windows-1252, Latin-1), decidir se vai habilitar a inferência de tipos e usar streaming para arquivos maiores que ~100 MB.