TL;DR — elige un método en 10 segundos
- Lo necesitas ya, sin instalar nada → FormatArc CSV a JSON (en el navegador, sin subir nada, admite UTF-8, Windows-1252, Latin-1 y otras codificaciones, comas entre comillas, saltos de línea incrustados)
- Scripting de shell / comandos de una línea →
csvjson data.csv(csvkit) omlr --icsv --ojson cat data.csv(Miller) - Dentro de una app de Python →
csv.DictReader(biblioteca estándar, sin dependencias) opandas.read_csvpara archivos grandes - Dentro de una app de Node.js → PapaParse con
{ header: true, dynamicTyping: true } - Dentro de un servicio en Go →
encoding/csvmás un pequeño bucle de cabeceras→mapa - Archivos grandes (1M+ filas) → procesa fila por fila con
csv.DictReader+ JSON Lines, nunca hagasjson.dumpde la lista completa
| Método | Instalación | Procesa archivos grandes | Inferencia de tipos | Salida NDJSON |
|---|---|---|---|---|
| FormatArc navegador | Ninguna | Hasta ~50 MB de memoria del navegador | Sí (configurable) | No (usa la CLI) |
Python csv.DictReader | biblioteca estándar | Sí (con bucle de escritura manual) | No (todo cadenas) | Sí |
pandas read_csv | pip install pandas | Por bloques con chunksize= | Sí (dtype inferido) | Sí (lines=True) |
Miller (mlr) | brew install miller | Sí (streaming) | Sí (--inumeric) | Sí (--ojsonl) |
csvkit (csvjson) | pip install csvkit | No (carga todo) | Sí (--no-inference para desactivar) | No |
| PapaParse (Node) | npm install papaparse | Sí (callback step) | Sí (dynamicTyping) | Sí (manual) |
Go encoding/csv | biblioteca estándar | Sí (bucle Read) | No (conversión manual) | Sí (manual) |
Esta guía cubre cada método con código funcional y luego las cuatro cosas que suelen dar problemas: la forma de la salida, la codificación, la inferencia de tipos y el rendimiento con archivos grandes.
Repaso del formato CSV (RFC 4180)
CSV significa Comma-Separated Values (valores separados por comas). El formato está especificado de manera informal por el RFC 4180Se abre en una pestaña nueva, pero en la práctica encontrarás muchas variantes. Un archivo CSV típico:
name,email,department,start_date
Alice Johnson,alice@example.com,Engineering,2024-01-15
Bob Smith,bob@example.com,Marketing,2023-06-01
Carol Williams,carol@example.com,Engineering,2024-03-10
La primera fila suele ser la cabecera. Cada fila posterior es un registro. Los campos se separan con comas, pero el formato tiene peculiaridades muy conocidas:
- Los campos que contienen comas deben ir entre comillas dobles:
"Smith, John" - Los campos que contienen comillas dobles deben escaparlas duplicándolas:
"She said ""hello""" - Los saltos de línea dentro de campos entrecomillados son válidos (y con frecuencia causan problemas a los analizadores ingenuos)
- No hay un estándar para la codificación: puedes recibir UTF-8, Windows-1252 (por defecto en Excel Windows para
es-ES/es-MX/es-AR), Latin-1, UTF-8 con BOM (por defecto en "CSV UTF-8" de Excel moderno) o codificaciones heredadas asiáticas (Shift-JIS, EUC-KR, GB2312) según la fuente - El propio carácter separador no está estandarizado: TSV usa tabulaciones, el Excel europeo usa
;, y algunos conjuntos de datos científicos usan|
Para más contexto sobre el formato y su historia, consulta Qué es CSV.
¿Por qué convertir CSV a JSON?
Surgen varias razones prácticas con regularidad:
- Las APIs REST aceptan cuerpos de petición en JSON, no en CSV. Si tienes datos en una hoja de cálculo que necesitas enviar por POST a una API, primero debes convertirlos.
- Los frameworks de frontend (React, Vue, Svelte) trabajan de forma natural con arrays y objetos JSON. Analizar CSV en el navegador es posible, pero añade una dependencia extra.
- Preservación de tipos: en CSV todo es una cadena. En JSON puedes distinguir entre números, booleanos, cadenas y null.
- Las bases de datos NoSQL como MongoDB, CouchDB y DynamoDB importan JSON Lines (NDJSON) directamente mediante cargadores masivos.
- Las canalizaciones de datos y herramientas ETL (Apache Airflow, Prefect, Mage, dbt) esperan cada vez más JSON o NDJSON como formato de intercambio entre etapas.
- Contexto para LLM: pasar datos tabulares a un LLM como objetos JSON es más fiable que como CSV, ya que el modelo reconoce las claves de forma consistente. Consulta Markdown vs HTML para LLMs para la guía de elección de formato.
Comprender ambos formatos te ayuda a tomar decisiones informadas. Consulta Qué es JSON para un análisis a fondo de la estructura y las capacidades de JSON.
5 formas de salida que podrías necesitar
La mayoría de los conversores de CSV a JSON producen exactamente una forma: un array de objetos con los valores de la cabecera como claves. Eso funciona para la mitad de los casos de uso. Para la otra mitad, necesitas una forma distinta. Aquí tienes el mismo CSV en las cinco formas para que elijas la adecuada.
Entrada:
id,name,score
1,Alice,95
2,Bob,87
3,Carol,92
Forma 1: Array de objetos (predeterminada en la mayoría de herramientas)
[
{ "id": 1, "name": "Alice", "score": 95 },
{ "id": 2, "name": "Bob", "score": 87 },
{ "id": 3, "name": "Carol", "score": 92 }
]
Mejor para: APIs REST, renderizado en el frontend, intercambio genérico de datos.
Forma 2: Objeto indexado (columna como clave primaria)
{
"1": { "name": "Alice", "score": 95 },
"2": { "name": "Bob", "score": 87 },
"3": { "name": "Carol", "score": 92 }
}
Mejor para: tablas de búsqueda, acceso por ID basado en diccionario. Se produce con Python:
import csv, json, sys
rows = list(csv.DictReader(sys.stdin))
result = {row["id"]: {k: v for k, v in row.items() if k != "id"} for row in rows}
json.dump(result, sys.stdout, indent=2)
Forma 3: JSON Lines / NDJSON (JSON delimitado por saltos de línea)
{"id":1,"name":"Alice","score":95}
{"id":2,"name":"Bob","score":87}
{"id":3,"name":"Carol","score":92}
Mejor para: ingesta en streaming (BigQuery, Snowflake COPY INTO, MongoDB mongoimport --type=json, canalizaciones de logs, productores de Kafka). Cada línea se analiza de forma independiente, así que puedes procesar un archivo de 10 GB fila por fila sin cargarlo todo en memoria.
Se produce con Miller: mlr --icsv --ojsonl cat data.csv. O con jq: jq -c '.[]' array.json > lines.ndjson.
Forma 4: Orientada a columnas (arrays paralelos)
{
"id": [1, 2, 3],
"name": ["Alice", "Bob", "Carol"],
"score": [95, 87, 92]
}
Mejor para: ciencia de datos (coincide con la disposición interna de Apache Arrow / pandas), canalizaciones en GPU, bases de datos columnares. Se produce con pandas: df.to_dict(orient="list").
Forma 5: Anidada mediante cabeceras delimitadas por barras
CSV de entrada con nombres de cabecera delimitados por barras:
id,name,address/city,address/zip
1,Alice,Tokyo,150-0001
2,Bob,Osaka,530-0001
Salida (anidada):
[
{ "id": 1, "name": "Alice", "address": { "city": "Tokyo", "zip": "150-0001" } },
{ "id": 2, "name": "Bob", "address": { "city": "Osaka", "zip": "530-0001" } }
]
Mejor para: producir cuerpos de petición de API que esperan estructuras anidadas. La mayoría de herramientas requieren posprocesamiento (consulta Salida JSON anidada más abajo).
Método 1: herramienta de navegador FormatArc (sin subir nada)
Si necesitas convertir un archivo CSV ahora mismo sin instalar nada, la herramienta CSV a JSON es la vía más rápida. Se ejecuta por completo en tu navegador: tus datos nunca salen de tu equipo.
- Abre CSV a JSON.
- Pega tu CSV en el panel izquierdo.
- Haz clic en Convertir. La salida JSON aparece en el panel derecho.
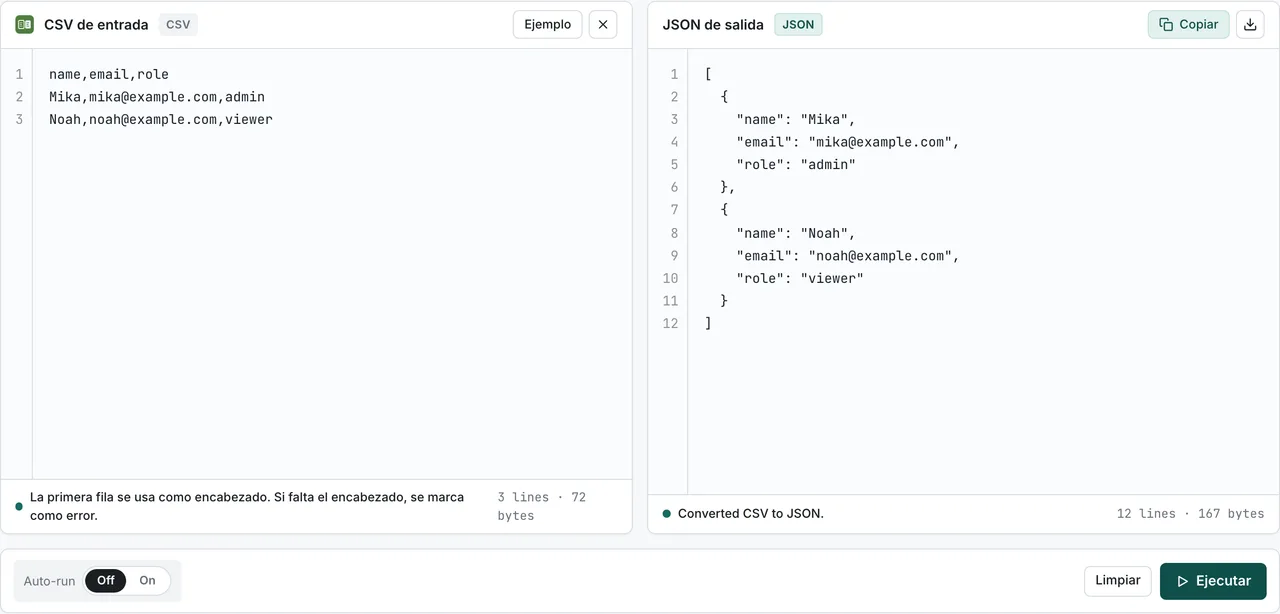
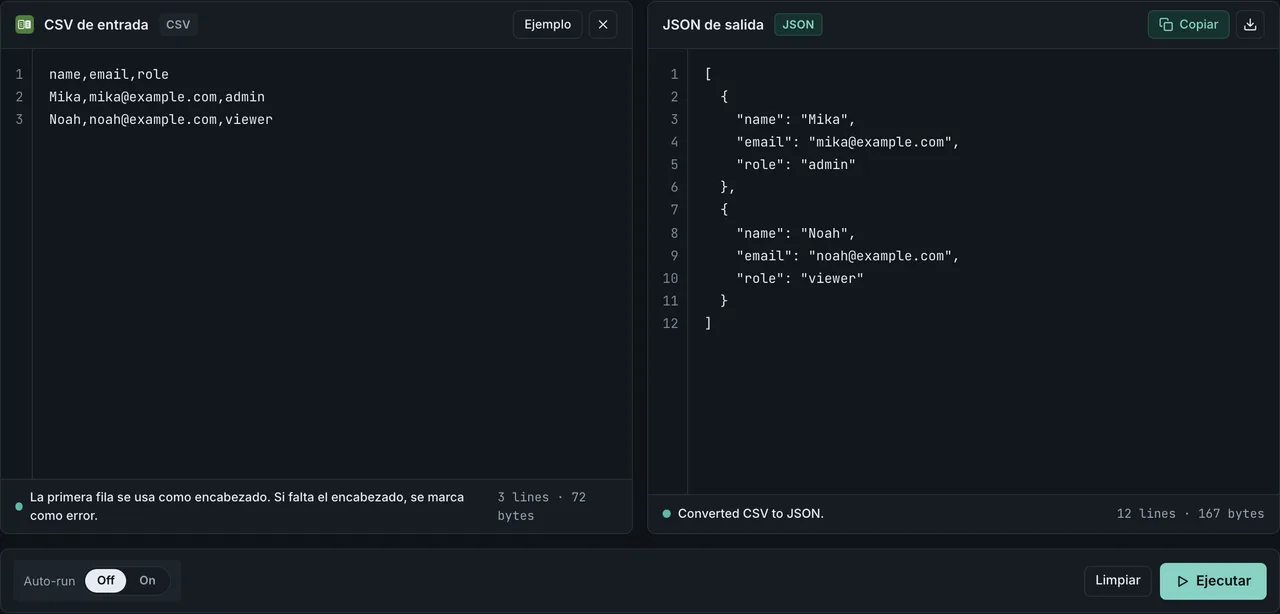
La herramienta gestiona casos límite que hacen tropezar a los conversores más simples: campos entrecomillados con comas incrustadas, campos que contienen saltos de línea, campos vacíos (convertidos en cadenas vacías) y conjuntos de datos grandes de hasta unos 50 MB según la memoria del navegador.
La conversión en el navegador importa cuando el CSV contiene datos sensibles: registros de clientes, tablas salariales, claves de API exportadas de un vault o cifras financieras internas. Todo lo que pegas permanece en la pestaña del navegador. No hay paso de subida ni procesamiento en el servidor.
Método 2: Python — csv.DictReader y pandas
Python incluye csv y json en su biblioteca estándar, así que no hacen falta paquetes de terceros para una conversión básica:
import csv
import json
import sys
reader = csv.DictReader(sys.stdin)
rows = list(reader)
json.dump(rows, sys.stdout, indent=2, ensure_ascii=False)
Guárdalo como csv2json.py y ejecuta:
python3 csv2json.py < data.csv > data.json
csv.DictReader usa la primera fila como cabecera automáticamente. Cada fila se convierte en un dict, y la lista de dicts se asigna a un array de objetos JSON. ensure_ascii=False es importante si tu CSV contiene caracteres no ASCII (japonés, latín acentuado, emoji); sin él, esos caracteres se escapan como secuencias あ.
Python con pandas (archivos grandes e inferencia de tipos)
import pandas as pd
df = pd.read_csv("data.csv", encoding="utf-8")
df.to_json("data.json", orient="records", indent=2, force_ascii=False)
orient="records" produce un array de objetos. Otros orients útiles: "index" (objeto indexado), "columns" (orientado a columnas), "values" (array de arrays).
Para archivos que no caben en memoria, usa chunksize para procesarlos por bloques:
import pandas as pd
with open("output.ndjson", "w") as out:
for chunk in pd.read_csv("huge.csv", chunksize=10000):
chunk.to_json(out, orient="records", lines=True, force_ascii=False)
out.write("\n")
Esto produce salida NDJSON y nunca mantiene más de 10.000 filas en memoria a la vez.
Método 3: Node.js — PapaParse
La biblioteca papaparse es el estándar de facto para analizar CSV en JavaScript. Es también lo que FormatArc usa internamente para la herramienta del navegador.
const Papa = require("papaparse");
const fs = require("fs");
const csv = fs.readFileSync("data.csv", "utf8");
const result = Papa.parse(csv, {
header: true,
dynamicTyping: true, // "42" → 42, "true" → true
skipEmptyLines: true,
});
fs.writeFileSync("data.json", JSON.stringify(result.data, null, 2));
Para archivos grandes, PapaParse admite streaming con un callback step:
const fs = require("fs");
const Papa = require("papaparse");
const stream = fs.createReadStream("huge.csv");
const out = fs.createWriteStream("huge.ndjson");
Papa.parse(stream, {
header: true,
dynamicTyping: true,
step: (row) => out.write(JSON.stringify(row.data) + "\n"),
complete: () => out.end(),
});
Cada fila se escribe en disco de inmediato, así que el uso de memoria se mantiene plano incluso en archivos de varios gigabytes.
Método 4: Go — encoding/csv
package main
import (
"encoding/csv"
"encoding/json"
"fmt"
"os"
)
func main() {
f, _ := os.Open("data.csv")
defer f.Close()
reader := csv.NewReader(f)
records, _ := reader.ReadAll()
headers := records[0]
result := make([]map[string]string, 0, len(records)-1)
for _, row := range records[1:] {
obj := make(map[string]string, len(headers))
for i, val := range row {
obj[headers[i]] = val
}
result = append(result, obj)
}
out, _ := json.MarshalIndent(result, "", " ")
fmt.Println(string(out))
}
El encoding/csv de Go trata cada campo como una cadena: no hay inferencia de tipos integrada. Si necesitas salida con tipos, analiza los valores manualmente (strconv.Atoi, strconv.ParseFloat, strconv.ParseBool).
Para procesar archivos grandes en streaming, sustituye ReadAll() por un bucle for que llame a Read() por cada fila y codifica cada fila a NDJSON con json.Marshal.
Método 5: Miller y csvkit (comandos de una línea)
Para scripting de shell y trabajo puntual, dos herramientas entregan la conversión de CSV a JSON con un solo comando.
Miller (mlr)
Miller es un procesador de datos en streaming: piensa en awk para datos estructurados:
# Array de objetos
mlr --icsv --ojson cat data.csv > data.json
# NDJSON (seguro para streaming)
mlr --icsv --ojsonl cat data.csv > data.ndjson
# Filtra y convierte en una sola pasada
mlr --icsv --ojson filter '$score > 90' data.csv
# Añade una columna calculada durante la conversión
mlr --icsv --ojson put '$grade = $score >= 90 ? "A" : "B"' data.csv
Instalación: brew install miller (macOS) o apt install miller (Debian/Ubuntu).
csvkit (csvjson)
csvkit es un conjunto de herramientas CSV escritas en Python:
pip install csvkit
csvjson data.csv > data.json
Opciones útiles:
--indent 2— salida con formato--no-inference— mantiene todos los valores como cadenas (no convierte números automáticamente)--stream— emite NDJSON en lugar de un array--locale ja_JP.UTF-8— para análisis de números sensible a la configuración regional
csvjson --stream es la vía más simple para obtener NDJSON sin escribir código.
Salida JSON anidada mediante cabeceras delimitadas por barras
La mayoría de los conversores producen objetos planos. Si tu consumidor posterior (API REST, esquema de Mongo, resolver de GraphQL) espera objetos anidados, necesitas un paso de posprocesamiento.
Una convención habitual es codificar el anidamiento en la cabecera con un separador como / o .:
id,name,address/city,address/zip,address/country
1,Alice,Tokyo,150-0001,JP
2,Bob,Osaka,530-0001,JP
Convierte y anida con Python:
import csv, json, sys
def nest(row, sep="/"):
result = {}
for key, val in row.items():
parts = key.split(sep)
cursor = result
for part in parts[:-1]:
cursor = cursor.setdefault(part, {})
cursor[parts[-1]] = val
return result
reader = csv.DictReader(sys.stdin)
rows = [nest(r) for r in reader]
json.dump(rows, sys.stdout, indent=2, ensure_ascii=False)
Salida:
[
{ "id": "1", "name": "Alice", "address": { "city": "Tokyo", "zip": "150-0001", "country": "JP" } },
{ "id": "2", "name": "Bob", "address": { "city": "Osaka", "zip": "530-0001", "country": "JP" } }
]
Para notación con punto (address.city en lugar de address/city), cambia el separador. El sitio web convertcsv.com popularizó esta convención con / y admite hasta 10 niveles de anidamiento.
Gestión de la codificación (BOM / Windows-1252 / Latin-1 / comas entre comillas / saltos de línea incrustados)
Los desajustes de codificación son, con diferencia, la causa más común de salidas de CSV a JSON con caracteres ilegibles. En países hispanohablantes lo más habitual es toparse con Windows-1252 (predeterminado del Excel en Windows en configuraciones regionales de España y América Latina) o UTF-8 con BOM (predeterminado de "CSV UTF-8" en Excel moderno).
UTF-8 con BOM
Excel en Windows guarda "CSV UTF-8" con una marca de orden de bytes (BOM): tres bytes (EF BB BF) al inicio del archivo. La mayoría de los analizadores JSON no eliminan el BOM, así que la primera clave de la salida acaba siendo name en lugar de name.
Elimínalo en Python:
with open("data.csv", encoding="utf-8-sig") as f: # -sig elimina el BOM
reader = csv.DictReader(f)
Elimínalo con Miller: mlr --icsv --ojson cat <(sed '1s/^\xEF\xBB\xBF//' data.csv).
Windows-1252 / Latin-1 (predeterminado del Excel en España y América Latina)
Excel en Windows guarda por defecto en Windows-1252 (una superserie de Latin-1 / ISO-8859-1) cuando el usuario elige "CSV" en el diálogo "Guardar como" en configuraciones regionales es-ES, es-MX, es-AR, pt-BR y similares. Si tu CSV contiene ñ, á, ¿, €, £ y ves caracteres ilegibles (ñ, é, €) al parsearlo como UTF-8, casi siempre es Windows-1252:
with open("data.csv", encoding="cp1252") as f: # o "latin-1" si no hay €/™/œ
reader = csv.DictReader(f)
Conversión de un paso desde el shell: iconv -f CP1252 -t UTF-8 data.csv > data.utf8.csv.
En la herramienta de navegador de FormatArc, pega texto UTF-8 directamente. Para archivos Windows-1252, conviértelos primero a UTF-8 con iconv o abre el archivo en tu editor y usa "Guardar como" → codificación "UTF-8".
Windows-1252 vs Latin-1: Windows-1252 añade 27 caracteres (€, curly quotes, œ, …) en el rango 0x80–0x9F que Latin-1 puro reserva para caracteres de control. Si tu texto contiene € o comillas tipográficas y Latin-1 falla, prueba Windows-1252.
Otras codificaciones heredadas: Shift-JIS, EUC-KR, GB2312
Si recibes CSV de socios en Japón, Corea o China, verás codificaciones heredadas específicas de la región:
- Shift-JIS — predeterminado del Excel japonés antes de "CSV UTF-8":
iconv -f SHIFT-JIS -t UTF-8oencoding="shift-jis"en Python - EUC-KR — coreano:
iconv -f EUC-KR -t UTF-8oencoding="euc-kr" - GB2312 / GBK / GB18030 — chino simplificado:
encoding="gb18030"(superserie que cubre los tres)
En todos los casos: convierte primero a UTF-8, luego parsea. No mezcles codificaciones en la misma canalización.
Comas entre comillas y saltos de línea incrustados
Los campos que contienen el carácter delimitador deben ir entre comillas:
id,description
1,"Hello, world"
2,"Multi-line
description here"
Un analizador ingenuo divide en cada coma y se rompe en la segunda fila. Usa un analizador de CSV apropiado (DictReader, PapaParse, Miller, csvkit): todos manejan correctamente el entrecomillado y los saltos de línea incrustados. Un string.split(",") hecho a mano no lo hace.
Delimitadores distintos de la coma (;, tabulaciones, barras verticales)
El Excel europeo suele usar ;. Especifica el delimitador explícitamente:
reader = csv.DictReader(f, delimiter=";")
mlr --csv --ifs ";" --ojson cat data.csv
Papa.parse(csv, { header: true, delimiter: ";" });
Para TSV (separado por tabulaciones): usa delimiter="\t" o --itsv en Miller.
Inferencia de tipos (analizar números / booleanos / nulls)
CSV almacena todo como texto. Que tu salida JSON preserve los tipos depende de la herramienta.
| Herramienta | Comportamiento por defecto | Cómo activar la inferencia |
|---|---|---|
csv.DictReader (biblioteca estándar de Python) | Todo cadenas | Conversión manual |
pandas read_csv | Inferido por columna | Activado por defecto; desactiva con dtype=str |
| PapaParse (Node) | Todo cadenas | { dynamicTyping: true } |
Miller (mlr) | Todo cadenas | Bandera --inumeric |
csvkit (csvjson) | Inferido | Desactiva con --no-inference |
| FormatArc navegador | Todo cadenas (predecible para ida y vuelta) | n/d |
Si activas la inferencia, ten cuidado con las sorpresas:
"007"se convierte en7(pérdida de ceros a la izquierda; malo para números de teléfono, códigos postales, ISBN)"NaN"e"Infinity"pueden convertirse en floats"true"/"false"/"yes"/"no"pueden convertirse en booleanos (PapaParse solo manejatrue/false, Miller es más estricto)- La cadena vacía
""puede convertirse ennull,"", u omitirse por completo según la herramienta - Los campos de ID que parecen numéricos se convierten en números, perdiendo precisión en los ID de más de 15 dígitos (el
Number.MAX_SAFE_INTEGERde JavaScript es2^53 - 1)
Valor predeterminado seguro: mantén todo como cadenas y conviértelo en el código de tu aplicación donde se conoce el esquema. La inferencia automática es cómoda para el análisis, pero insegura para canalizaciones de datos en producción.
Rendimiento y archivos grandes
Para archivos de menos de 10.000 filas, cualquier método funciona. Las diferencias aparecen a gran escala.
| Tamaño del archivo | Método recomendado | Por qué |
|---|---|---|
| Menos de 10 MB | Herramienta de navegador, csvkit, pandas | Todos caben en memoria con comodidad |
| 10–500 MB | pandas chunksize, Miller, streaming de PapaParse, Go | Procesa fila por fila, nunca carga el archivo entero |
| 500 MB+ | Miller, Go, Python csv.DictReader + salida NDJSON | Se requiere streaming de memoria constante |
Rendimiento medido (Apple M5 Pro / 64 GB / macOS 26.5, CSV de 5 columnas × 1.000.000 de filas, un solo hilo; reproducible con scripts/benchmarks/csv-to-json-throughput/ del repositorio):
- Python
csv.DictReader+json.dump(Python 3.14.6): ~232.000 filas/s - pandas
read_csv+to_json(pandas 3.0.3): ~1.113.000 filas/s - Miller
mlr --c2j(Miller 6.19.0): ~1.960.000 filas/s (mediana en caliente de 5 ejecuciones; la primera ejecución en frío cae a ~990.000 filas/s por el fallo de caché de archivos) - Go
encoding/csv+encoding/json(Go 1.26.4): ~2.058.000 filas/s - Streaming de PapaParse (papaparse 5.5.2 / Node 26.3.1): ~1.626.000 filas/s
- FormatArc en el navegador: mismo motor PapaParse 5.5, pero limitado por la capacidad de respuesta del hilo principal y la memoria de la página, así que el techo en el navegador queda muy por debajo de las cifras del CLI; cómodo en decenas de MB / cientos de miles de filas
Estas cifras dependen mucho del hardware, del SO y de la versión de cada herramienta. En un portátil Intel de 2021, con pandas 2.x o Miller 5.x, el rendimiento suele ser menos de la mitad: vuelve a medir en tu propia máquina antes de tomar una decisión.
Para datos a escala de terabytes, ninguno de estos es la herramienta adecuada: usa Apache Spark, DuckDB (COPY data FROM 'data.csv' (FORMAT CSV) y luego COPY (SELECT * FROM data) TO 'out.ndjson' (FORMAT JSON, ARRAY false)), o Apache Arrow directamente.
Patrón de streaming para archivos arbitrariamente grandes (Python)
import csv
import json
import sys
writer = sys.stdout
reader = csv.DictReader(open("huge.csv", encoding="utf-8"))
for row in reader:
writer.write(json.dumps(row, ensure_ascii=False) + "\n")
Esto emite NDJSON. Cada fila usa una cantidad fija de memoria independientemente del tamaño de la entrada. Canalízalo directamente a BigQuery, S3 o gzip -c > out.ndjson.gz.
Flujo de trabajo CI/CD (curl POST y GitHub Actions)
Un caso de uso común en producción: convertir un CSV mantenido en Git a JSON y enviarlo por POST a una API en cada push.
# Convertir
python3 csv2json.py < users.csv > users.json
# Enviar por POST a una API
curl -X POST https://api.example.com/users/bulk \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_TOKEN" \
-d @users.json
Ejemplo de GitHub Actions:
name: Sync user CSV to API
on:
push:
paths: ["data/users.csv"]
jobs:
sync:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Install Miller
run: sudo apt-get install -y miller
- name: Convert and upload
env:
API_TOKEN: ${{ secrets.API_TOKEN }}
run: |
mlr --icsv --ojson cat data/users.csv > users.json
curl -fsS -X POST https://api.example.com/users/bulk \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $API_TOKEN" \
-d @users.json
Para pruebas puntuales de API, pega el CSV en la herramienta CSV a JSON, copia la salida y pégala en Postman, Insomnia o curl --data.
Si además necesitas dar formato al JSON resultante antes de enviarlo, consulta Consejos para formatear JSON: opciones de indentación, orden de claves y minificación que mantienen revisables las cargas útiles de la API.
Preguntas frecuentes
Excel exporta CSV, ¿FormatArc gestiona el BOM?
Sí. La herramienta de navegador detecta y elimina el BOM de UTF-8 automáticamente. Para Python, usa encoding="utf-8-sig". Para Node.js, la biblioteca papaparse gestiona el BOM de forma transparente.
¿Puedo obtener salida NDJSON (JSON Lines)?
La herramienta de navegador de FormatArc emite actualmente un array JSON. Para NDJSON, usa Miller (mlr --icsv --ojsonl) o csvkit (csvjson --stream). Son las herramientas estándar para canalizaciones de logs e importaciones masivas a bases de datos.
¿Cómo convierto un CSV sin cabecera?
Para csv.DictReader, pasa fieldnames=["col1", "col2", ...] explícitamente:
reader = csv.DictReader(f, fieldnames=["id", "name", "score"])
Para PapaParse: Papa.parse(csv, { header: false }) devuelve un array de arrays. Luego asigna tú mismo cada fila a un objeto.
¿Por qué mis ID numéricos salen como cadenas?
La mayoría de las herramientas usan por defecto la salida en cadenas por seguridad. Para obtener números, activa la inferencia de tipos: dynamicTyping: true (PapaParse), --inumeric (Miller) o dtype en pandas. Ojo: los ID de más de 15 dígitos pierden precisión en JavaScript / JSON por los límites del float de doble precisión.
¿Por qué veo  al inicio de mis claves JSON?
Eso es el BOM de UTF-8 mostrado como caracteres Latin-1. Elimínalo leyendo el archivo con encoding="utf-8-sig" (Python) o con un preprocesamiento mediante sed '1s/^\xEF\xBB\xBF//' data.csv.
¿Cuál es el archivo CSV más grande que puedo convertir en el navegador?
En la práctica, unos 50 MB en un portátil típico. Los navegadores mantienen en memoria el texto completo y el resultado analizado, más la memoria de trabajo del analizador. Para archivos más grandes, usa Miller, pandas con chunksize o un programa en Go: todos procesan en streaming y no tienen límite superior más allá del espacio en disco.
¿Cómo convierto un CSV con valores JSON anidados dentro de una celda?
Si una celda del CSV contiene JSON como "{""key"":""value""}", analízalo primero como cadena y luego aplica json.loads() al resultado. Con pandas:
import pandas as pd, json
df = pd.read_csv("data.csv")
df["metadata"] = df["metadata"].apply(json.loads)
df.to_json("data.json", orient="records", force_ascii=False)
¿Puedo preservar el orden de las columnas en la salida JSON?
Sí, con todas las herramientas modernas que se mencionan aquí. Los dicts de Python preservan el orden de inserción desde la 3.7, csv.DictReader usa el orden de la fila de cabecera y pandas to_json(orient="records") respeta el orden de las columnas. json.dump no reordena las claves a menos que pases sort_keys=True.
Guías relacionadas
- Qué es CSV — historia del formato, RFC 4180 y dialectos comunes
- Qué es JSON — el modelo de datos y los tipos de JSON
- Conversión de CSV a tabla Markdown — cuando prefieres una tabla legible en lugar de eso
- Conversión de JSON a YAML — el siguiente paso si tu consumidor posterior es Kubernetes o Docker Compose
- Conversor de JSON a YAML — pega el JSON que acabas de generar para producir YAML de Kubernetes, Docker Compose u OpenAPI en el navegador
- Consejos para formatear JSON — produce JSON revisable después de la conversión
- curl pretty print de JSON — probar la salida convertida contra APIs
Resumen
La conversión de CSV a JSON es una tarea rutinaria con un método para cada situación:
- Sin instalar, datos sensibles: FormatArc CSV a JSON — en el navegador, sin subir nada, gestiona las peculiaridades de codificación.
- Canalizaciones de shell: Miller (
mlr --icsv --ojson) o csvkit (csvjson). - Aplicaciones en Python:
csv.DictReaderpara la biblioteca estándar; pandas para archivos grandes e inferencia de tipos. - Aplicaciones en Node.js: PapaParse con
dynamicTypingy el callback de streamingsteppara archivos grandes. - Servicios en Go:
encoding/csvmás un pequeño bucle de cabeceras→mapa.
Las cuatro cosas que hay que acertar: elegir la forma de salida adecuada (array vs NDJSON vs indexado vs columna vs anidado), hacer coincidir la codificación de entrada (UTF-8 con BOM, Windows-1252, Latin-1), decidir si activar la inferencia de tipos y usar streaming para archivos mayores de ~100 MB.