Colar uma página da web bruta no ChatGPT, no Claude ou no Gemini funciona, mas você quase sempre paga por isso duas vezes: em tokens e em qualidade da resposta. O HTML que você copiou está cheio de divs de empacotamento, atributos class, scripts inline e pixels de rastreamento, e nada disso o modelo precisa para entender o conteúdo. O Markdown remove tudo isso e deixa o modelo apenas com a estrutura e o texto.
Este guia compara Markdown e HTML como formatos de entrada para LLMs com números medidos, lista os casos em que o HTML ainda é a escolha certa e mostra um caminho de conversão no navegador que não faz upload do HTML interno para um servidor de terceiros.
Resposta rápida
Para entrada de LLM, prefira Markdown. Ele usa aproximadamente de um terço a um décimo dos tokens de um HTML equivalente, e benchmarks externos mostram maior precisão em tabelas, listas e blocos de código. Cole seu HTML em HTML to Markdown e copie o resultado para o seu prompt. A conversão roda inteiramente no seu navegador: o HTML que você cola não é enviado para o FormatArc nem para qualquer serviço de terceiros.
Como as LLMs leem formatos
As LLMs não "veem" o HTML renderizado da forma como um navegador vê. Elas processam o código-fonte bruto como um fluxo de tokens. Cada colchete angular, nome de classe e estilo inline consome tokens da mesma janela de contexto em que o seu conteúdo de verdade precisa caber.
Daí decorrem duas consequências:
- Uma página HTML cheia de empacotamento deixa menos espaço para instruções, exemplos e a resposta do assistente.
- O ruído dentro do código-fonte, como
class="text-base text-gray-700", atributosdata-*e trechos de analytics, pode desviar a atenção do modelo do conteúdo que ele deveria extrair ou reescrever.
O Markdown codifica a mesma estrutura (títulos, listas, links, código) com um ou dois sinais de pontuação por elemento, em vez de tags de abertura e fechamento. O resultado é mais curto e mais coerente com os padrões que as LLMs encontram nos corpora de treinamento: arquivos README do GitHub, sites de documentação, posts do Stack Overflow e tópicos de fórum são predominantemente Markdown.
O motivo estrutural de o Markdown ser mais enxuto é o próprio modelo de tags. No HTML que você realmente copia de uma página (DOM serializado ou saída de um CMS), a maioria dos elementos de contêiner chega como um par de tags casadas (<p>...</p>, <li>...</li>, <td>...</td>, <div>...</div>), de modo que o custo da marcação é pago duas vezes por elemento: uma para abrir e outra para fechar. (Tecnicamente, o HTML permite omitir algumas dessas tags de fechamento, mas a serialização do DOM renderizado e os motores de template as emitem mesmo assim, e é isso que você cola.) O aninhamento multiplica esse efeito: uma lista dentro de uma célula de tabela dentro de uma linha empilha tags de abertura na entrada e tags de fechamento na saída, e cada tag ainda pode carregar atributos class, id, style e data-* que adicionam mais caracteres sem acrescentar o significado de que o modelo precisa. O Markdown expressa as mesmas construções como marcadores únicos e sem par, colocados uma só vez: # para um título, - para um item de lista, | para o limite de uma coluna de tabela, uma linha em branco para uma quebra de parágrafo. Não há token de fechamento para repetir nem espaço de atributo para preencher, então a sobrecarga por elemento é uma pequena constante, em vez de um par de contêiner que cresce com os atributos e a profundidade de aninhamento. É essa diferença que as medições abaixo quantificam; a causa é a ausência da duplicação de tags de abertura e fechamento.
As próprias construções são definidas por especificações publicadas: a sintaxe central (títulos, listas, links, spans de código e código cercado, parágrafos) é padronizada na CommonMark SpecificationAbre em uma nova aba, e as extensões de tabela, lista de tarefas, texto tachado e autolink são definidas na GitHub Flavored Markdown SpecAbre em uma nova aba. Ambos são documentos estáveis e versionados, o que em parte explica por que o Markdown é tão consistente nos corpora públicos com os quais esses modelos são treinados.
A composição exata do treinamento de cada modelo não é pública, então não convém exagerar aqui. O que é verificável é que o Markdown é amplamente usado em textos técnicos públicos, e os principais provedores de modelos recomendam explicitamente uma estrutura no estilo Markdown em seus guias de prompting. Por exemplo, a documentação de prompting do Claude da Anthropic e o guia de design de prompts do Gemini do Google sugerem usar títulos e listas com marcadores para separar seções.
Eficiência de tokens: uma comparação medida
Para comparar formatos de forma justa, escrevemos um pequeno documento técnico sintético que explica o que é JSON. O documento contém um título h2, dois ou três parágrafos, uma lista com três marcadores, um bloco de código JSON e uma tabela de três colunas. Em seguida, expressamos o mesmo conteúdo de três maneiras: uma versão HTML usando o padrão de empacotamento que você vê em uma página típica de CMS (classes no estilo Tailwind e atributos aria), uma versão Markdown usando CommonMark mais a extensão de tabelas do GFMAbre em uma nova aba e uma versão em texto puro com a marcação removida e a tabela expressa como linhas separadas por tabulação. Os três arquivos, o script de medição e o JSON de resultados estão comitados no repositório em scripts/benchmarks/markdown-vs-html-for-llms/. O texto completo dos três também é mostrado no final desta seção.
As contagens de tokens vêm da biblioteca oficial tiktokenAbre em uma nova aba da OpenAI, versão 0.13.0. cl100k_base é o tokenizador da família GPT-3.5 / GPT-4; o200k_base é usado pela família GPT-4o.
| Formato | Caracteres (UTF-8) | Bytes | Tokens cl100k_base | Tokens o200k_base |
|---|---|---|---|---|
| HTML (DOM renderizado com classes e aria) | 2.911 | 2.911 | 832 | 835 |
| Markdown (GFM) | 1.071 | 1.071 | 243 | 247 |
| Texto puro (tags removidas) | 986 | 986 | 213 | 217 |
Redução em relação ao HTML: Markdown −63,2 % de caracteres, −70,8 % de tokens cl100k, −70,4 % de tokens o200k; texto puro −66,1 % de caracteres, −74,4 % de tokens cl100k, −74,0 % de tokens o200k. A proporção caracteres por token fica em 3,50 para HTML, 4,41 para Markdown e 4,63 para texto puro: o HTML carregado de símbolos (<, >, =, ", nomes de atributos) prejudica de forma mensurável a eficiência do tokenizador. Os tokenizadores do Claude e do Gemini diferem em seus valores absolutos, mas a direção do imposto de empacotamento é a mesma para qualquer tokenizador BPE.
Estes são números para um documento sintético específico. A web é mais bagunçada do que esta amostra, e medições externas em páginas reais relatam diferenças mais acentuadas:
- O benchmark da Web2MDAbre em uma nova aba: redução média de 87,5 % de tokens em seis tipos representativos de páginas; em um artigo de 3.000 palavras, HTML ≈ 8.000 tokens vs Markdown ≈ 2.800 tokens (-67 %).
- O artigo de 2026 da Beam.aiAbre em uma nova aba: 68 % de redução de tokens em conteúdo limpo, chegando a 87 % em páginas reais com toda a estrutura do DOM.
- A análise da ReleasePadAbre em uma nova aba: redução de 10 a 20 % em listas simples com marcadores, escalando fortemente conforme a densidade de empacotamento aumenta.
Em qual benchmark você confiar, a direção é a mesma: o HTML paga um imposto de empacotamento que o Markdown evita, e esse imposto se acumula em prompts pesados em contexto, nos quais você quer encaixar vários documentos em uma única janela.
Os documentos de amostra exatos
Versão HTML (2.911 caracteres / 832 tokens cl100k)
<section class="prose prose-lg max-w-none">
<h2 class="text-2xl font-semibold mt-8 mb-4" id="what-is-json">What is JSON?</h2>
<p class="text-base text-gray-700 leading-relaxed mb-4">JSON (JavaScript Object Notation) is a lightweight, text-based data format used to exchange structured data between systems. It originated in JavaScript but is now language-independent and supported by virtually every modern programming language.</p>
<p class="text-base text-gray-700 leading-relaxed mb-4">A JSON document is built from a small set of building blocks:</p>
<ul class="list-disc pl-6 mb-4 space-y-1">
<li class="text-base text-gray-700">Objects: unordered collections of key-value pairs wrapped in <code class="bg-gray-100 px-1 rounded">{}</code></li>
<li class="text-base text-gray-700">Arrays: ordered lists of values wrapped in <code class="bg-gray-100 px-1 rounded">[]</code></li>
<li class="text-base text-gray-700">Primitives: strings, numbers, booleans, and <code class="bg-gray-100 px-1 rounded">null</code></li>
</ul>
<p class="text-base text-gray-700 leading-relaxed mb-4">Here is a minimal example representing a single user record:</p>
<pre class="bg-gray-900 text-gray-100 p-4 rounded overflow-x-auto mb-4"><code class="language-json">{
"id": 42,
"name": "Ada Lovelace",
"active": true
}</code></pre>
<p class="text-base text-gray-700 leading-relaxed mb-4">The core value types and their typical use cases are summarized below.</p>
<table class="w-full border-collapse mb-4" aria-label="JSON value types">
<thead>
<tr class="border-b border-gray-300">
<th class="text-left p-2 font-semibold">Type</th>
<th class="text-left p-2 font-semibold">Example</th>
<th class="text-left p-2 font-semibold">Typical use</th>
</tr>
</thead>
<tbody>
<tr class="border-b border-gray-200">
<td class="p-2"><code class="bg-gray-100 px-1 rounded">string</code></td>
<td class="p-2"><code class="bg-gray-100 px-1 rounded">"hello"</code></td>
<td class="p-2">Names, labels, free text</td>
</tr>
<tr class="border-b border-gray-200">
<td class="p-2"><code class="bg-gray-100 px-1 rounded">number</code></td>
<td class="p-2"><code class="bg-gray-100 px-1 rounded">3.14</code></td>
<td class="p-2">IDs, counts, measurements</td>
</tr>
<tr class="border-b border-gray-200">
<td class="p-2"><code class="bg-gray-100 px-1 rounded">boolean</code></td>
<td class="p-2"><code class="bg-gray-100 px-1 rounded">true</code></td>
<td class="p-2">Flags, feature toggles</td>
</tr>
</tbody>
</table>
<p class="text-base text-gray-700 leading-relaxed mb-4">JSON is widely used for REST API payloads, configuration files, and persisting application state because it is easy to read, easy to parse, and supported everywhere.</p>
</section>
Versão Markdown / CommonMark + GFM (1.071 caracteres / 243 tokens cl100k)
## What is JSON?
JSON (JavaScript Object Notation) is a lightweight, text-based data format used to exchange structured data between systems. It originated in JavaScript but is now language-independent and supported by virtually every modern programming language.
A JSON document is built from a small set of building blocks:
- Objects: unordered collections of key-value pairs wrapped in `{}`
- Arrays: ordered lists of values wrapped in `[]`
- Primitives: strings, numbers, booleans, and `null`
Here is a minimal example representing a single user record:
```json
{
"id": 42,
"name": "Ada Lovelace",
"active": true
}
```
The core value types and their typical use cases are summarized below.
| Type | Example | Typical use |
| --- | --- | --- |
| string | `"hello"` | Names, labels, free text |
| number | `3.14` | IDs, counts, measurements |
| boolean | `true` | Flags, feature toggles |
JSON is widely used for REST API payloads, configuration files, and persisting application state because it is easy to read, easy to parse, and supported everywhere.
Versão em texto puro (986 caracteres / 213 tokens cl100k)
What is JSON?
JSON (JavaScript Object Notation) is a lightweight, text-based data format used to exchange structured data between systems. It originated in JavaScript but is now language-independent and supported by virtually every modern programming language.
A JSON document is built from a small set of building blocks:
Objects: unordered collections of key-value pairs wrapped in {}
Arrays: ordered lists of values wrapped in []
Primitives: strings, numbers, booleans, and null
Here is a minimal example representing a single user record:
{
"id": 42,
"name": "Ada Lovelace",
"active": true
}
The core value types and their typical use cases are summarized below.
Type Example Typical use
string "hello" Names, labels, free text
number 3.14 IDs, counts, measurements
boolean true Flags, feature toggles
JSON is widely used for REST API payloads, configuration files, and persisting application state because it is easy to read, easy to parse, and supported everywhere.
Os três arquivos-fonte, o script de medição baseado em tiktoken da OpenAI (measure.py) e o JSON de resultados estão comitados no repositório em scripts/benchmarks/markdown-vs-html-for-llms/. Execute python3 -m venv venv && ./venv/bin/pip install tiktoken==0.13.0 && ./venv/bin/python measure.py para reproduzir exatamente os números da tabela acima.
Privacidade: mantenha o HTML sensível fora de serviços de terceiros
Os argumentos de tokens e de precisão já foram bastante repetidos em outros artigos. O ângulo que a maioria deles pula é o que acontece com o HTML de origem durante a etapa de conversão.
Muitos conversores online de "HTML para Markdown" executam a conversão em um servidor de backend. Você cola seu HTML, a página faz um POST para uma API, o servidor devolve o Markdown. Isso é aceitável para um trecho público da Wikipedia. Não é aceitável para:
- Uma página de documentação interna exportada do Confluence ou do Notion.
- O dump de HTML de um painel administrativo que contém nomes de clientes.
- O corpo de uma resposta de um site de staging antes de o texto de marketing ser aprovado.
- Qualquer corpo de e-mail em HTML com dados pessoais.
O HTML to Markdown do FormatArc é uma página estática. A conversão para Markdown é implementada em JavaScript que roda no seu navegador, usando a biblioteca TurndownAbre em uma nova aba embutida na página. O HTML que você cola é processado localmente; nenhuma requisição de rede leva o HTML de origem para o FormatArc ou para qualquer serviço de terceiros. Você mesmo pode verificar isso abrindo a aba de rede no DevTools do navegador, colando uma string identificável de forma única no painel de HTML, pressionando Run e confirmando que nenhuma requisição de saída contém a sua string.
"No navegador" aqui significa que o HTML de origem não é enviado. A própria página continua sendo servida por HTTPS a partir de uma CDN, e analytics padrão podem ser carregados uma vez na primeira visita, mas o documento que você converte nunca sai da sua máquina.
Qualidade de compreensão: tabelas, código e listas
A contagem de tokens é a metade fácil. A qualidade de compreensão é a metade que decide se o seu prompt realmente funciona.
Benchmarks publicados tendem a favorecer o Markdown em três tarefas comuns:
- Extração de tabelas: como cita a análise da ReleasePadAbre em uma nova aba, uma avaliação baseada em GPT frequentemente referenciada relata ~60,7 % de precisão em tabelas Markdown vs ~53,6 % em tabelas HTML equivalentes, uma diferença de 7 pontos sobre dados subjacentes idênticos.
- Tratamento de blocos de código: o código cercado em Markdown com uma dica de linguagem (
```python) preserva o sinal da linguagem de forma limpa; o HTML frequentemente aninha a dica de linguagem dentro de um atributo de classe (<pre><code class="language-python">), que o modelo precisa extrair da marcação. - Listas aninhadas: a indentação do Markdown oferece uma pista estrutural forte com baixo custo de tokens. As cadeias HTML
<ul><li><ul><li>queimam tokens e ocasionalmente confundem o modelo sobre a qual lista um item filho pertence.
Nada disso significa que o Markdown seja universalmente mais preciso (veja na próxima seção onde o HTML vence), mas para o padrão cotidiano de "resuma este artigo", "extraia estes campos" ou "reescreva esta seção", os dados de compreensão apontam na mesma direção que os dados de tokens.
Onde o HTML ainda é a escolha certa
O Markdown nem sempre é a resposta. Há três cenários em que colar HTML é genuinamente melhor:
Quando a semântica vive nos atributos
aria-label, role, itemprop, microdados e tags Open Graph carregam informação que não tem equivalente em Markdown. Se você está pedindo ao modelo para auditar acessibilidade, extrair metadados estruturados de produto ou verificar marcação schema.org, os atributos HTML são o conteúdo. Removê-los com um conversor de Markdown destrói a tarefa.
Quando você precisa do layout visual, não apenas do texto
Diagramas SVG, gráficos incorporados, widgets <iframe>, atributos de dados personalizados para componentes interativos, tudo isso sobrevive no HTML e desaparece no Markdown. Em maio de 2026, Thariq Shihipar, da Anthropic, publicou Using Claude Code: The Unreasonable Effectiveness of HTMLAbre em uma nova aba, defendendo que, para agentes de IA que produzem saídas ricas voltadas para humanos, a amplitude expressiva do HTML (layouts estilizados, elementos interativos, SVG incorporado) compensa o seu custo mais alto de tokens. O ponto se aplica simetricamente: se a sua entrada contém elementos visuais sobre os quais o modelo precisa raciocinar, envie HTML.
Quando o modelo vai renderizar o resultado
Se você está pedindo ao modelo para produzir uma saída que será renderizada de volta em um navegador, às vezes é mais simples manter HTML de ponta a ponta e pular o passo intermediário em Markdown. Isso é principalmente uma questão de ferramentas: o Markdown faz o ida e volta bem o suficiente para raramente forçar uma decisão.
Um fluxo de trabalho prático: de HTML para Markdown pronto para LLM
Para o caso comum, em que você tem uma página da web ou um e-mail em HTML e quer entregar o conteúdo a uma LLM sem o imposto da marcação, aqui está o fluxo de trabalho que mantém os dados localmente.
Passo 1: Obtenha o HTML
No Chrome ou no Firefox, clique com o botão direito na página e escolha "Exibir código-fonte da página", ou use o painel Elements do DevTools e copie o HTML externo do elemento <article> ou <main>. Para e-mail em HTML, use "Ver código-fonte" no seu cliente de e-mail.
Se você só precisa do corpo do artigo, copie essa subárvore em vez da página inteira. Remover a navegação, a barra lateral e o rodapé nesta etapa reduz o orçamento de tokens mais do que qualquer conversão inteligente feita depois.
Passo 2: Converta no seu navegador
Cole em HTML to Markdown e pressione Run. O Markdown aparece no painel da direita.
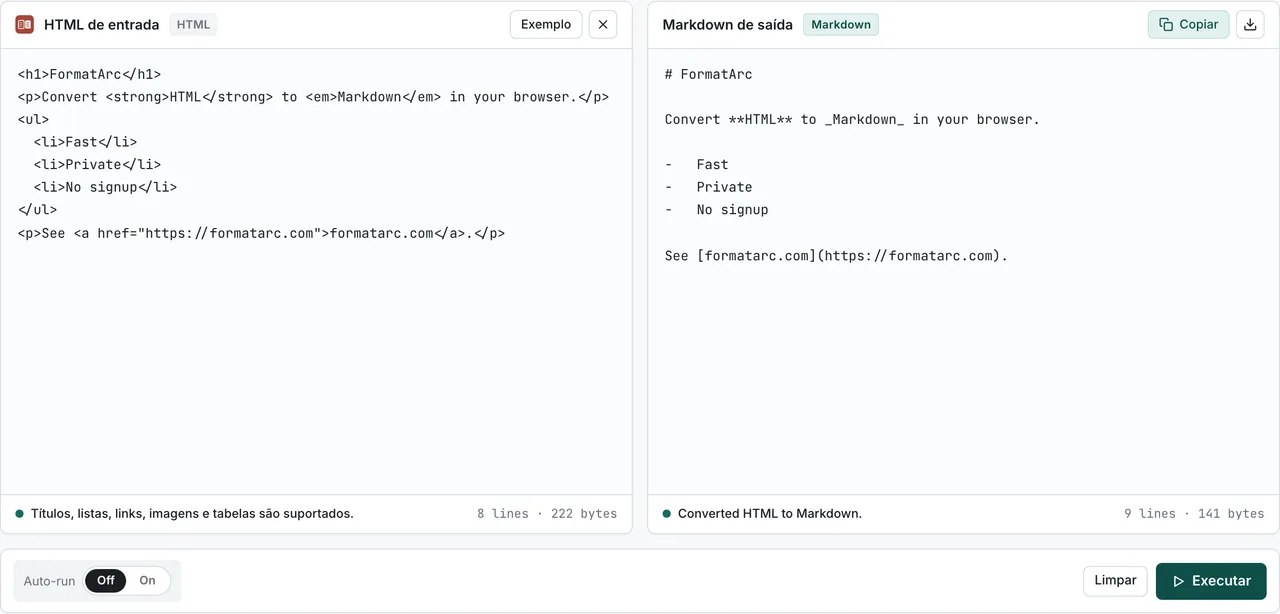
Para um passo a passo mais detalhado da conversão em si, com tabelas, caminhos de imagem e casos extremos de colspan, veja o guia de HTML para Markdown. Para o caminho inverso, quando a LLM responde com Markdown que você quer de volta como HTML, o Markdown to HTML também trata disso localmente.
Passo 3: Limpe antes de colar
Mesmo depois da conversão, examine o Markdown em busca de resíduos que você não precisa:
- Links de navegação que se converteram em itens de lista no topo.
- Banners de consentimento de cookies que ainda deixaram um parágrafo para trás.
- Blocos de copyright no rodapé.
Dois minutos de limpeza manual normalmente recuperam mais contexto do que qualquer etapa automatizada adicional.
Passo 4: Crie o prompt com o Markdown já limpo
Um modelo simples que funciona para a maioria das tarefas de extração:
Below is a documentation page in Markdown.
Task: <one sentence>.
Constraints: <output format, length, etc.>.
---
<paste the cleaned Markdown here>
Os títulos do Markdown dão ao modelo âncoras fortes para referenciar na resposta ("Na seção 'Sintaxe'..."), o que melhora a especificidade da resposta.
Armadilhas ao converter HTML para entrada de LLM
Cinco coisas costumam dar errado. Fique atento a estas:
- Blocos de código perdendo a dica de linguagem.
<pre><code class="language-python">deveria virar```python. Alguns conversores descartam a dica, o que força o modelo a adivinhar a linguagem. - Tabelas com
colspanourowspandesabando. As tabelas com pipe do GFM são estritamente retangulares, então células mescladas acabam achatadas. Para tabelas de dados, considere converter via CSV to Markdown em vez disso; o guia de CSV para Markdown detalha a conversão. Veja também a folha de referência de sintaxe de tabelas Markdown e a folha de referência de tabelas GFM para alinhamento e escape. - HTML inline vazando. Tanto o CommonMark quanto o GFM permitem HTML bruto inline. Se o modelo vai ver
<span class="text-red">important</span>no seu "Markdown", isso voltou ao balde do imposto de empacotamento. Use um conversor que emita Markdown puro nos casos em que conseguir, e mantenha HTML bruto apenas para as construções (notação matemática, tabelas complexas) que genuinamente precisam dele. - Caminhos relativos de imagem e link.
<img src="/images/foo.png">vira, que a LLM não consegue buscar. Reescreva os caminhos para URLs absolutas ou avise no prompt que as imagens estão indisponíveis. - Incompatibilidade entre CommonMark e GFM. Tabelas, listas de tarefas, texto tachado e autolinks são extensões do GFM. Se a sua ferramenta a jusante for CommonMark estrito, esses recursos não serão renderizados. Veja CommonMark vs GFM para entender o limite.
Comparação de formatos em um relance
Para os impacientes, aqui está a matriz de decisão:
| Formato | Quando usar como entrada de LLM | Custo de tokens | Ponto forte | Ponto fraco |
|---|---|---|---|---|
| Markdown | Padrão para a maioria dos prompts: docs, artigos, READMEs, logs de chat | Baixo | Pistas estruturais combinam com os dados de treinamento; tabelas, listas e código preservados | Perde a semântica de atributos, sem estilização inline |
| Texto puro | Extração de texto pura, tarefas tipo OCR | O menor | Menor pegada | A estrutura se perde; ruim para listas ou tabelas |
| HTML | Auditorias de acessibilidade, schema.org / microdados, raciocínio sobre layout visual | O maior | Carrega atributos, semântica, mídia incorporada | Imposto de empacotamento; ruído distrai o modelo |
| JSON | Registros estruturados, respostas de API, payloads de chamada de função | Médio | Esquema sem ambiguidade; o modelo consegue reconhecer padrões nas chaves | Verboso para prosa; sobrecarga de aspas |
| XML | A Anthropic recomenda tags XML para seções de prompt no Claude | Médio | Limites explícitos entre as partes do prompt | Verboso; a estrutura do CommonMark costuma ser suficiente |
Para a maioria dos prompts cotidianos, como "resuma este artigo", "extraia estes campos" ou "reescreva em linguagem simples", o Markdown é o padrão certo.
Perguntas frequentes
Devo usar Markdown ou texto puro como contexto para o ChatGPT?
Markdown se a fonte tiver qualquer estrutura (títulos, listas, tabelas, código). Texto puro se for realmente prosa sem estrutura. O texto puro é o mais barato, mas descarta as pistas estruturais que ajudam o modelo a navegar por contextos mais longos.
O Claude entende Markdown melhor do que HTML?
O Claude lida com ambos. As orientações de prompting da Anthropic recomendam títulos e listas no estilo Markdown para separar seções do prompt e, além disso, incentivam tags XML (<instructions>, <context>) como limites entre as partes do prompt. O Markdown ainda vence em eficiência de tokens para o conteúdo em si; o XML é útil em torno do conteúdo, como estrutura.
E quanto a JSON ou XML para contexto estruturado?
Use JSON quando os dados forem naturalmente tabulares ou em forma de registros (respostas de API, configuração). Use XML quando quiser limites explícitos entre seções do prompt; a documentação da Anthropic usa esse estilo. Para prosa, nenhum deles supera o Markdown em custo de tokens.
Como converto uma URL diretamente para Markdown pronto para LLM?
Não há uma forma totalmente no lado do cliente de buscar uma URL arbitrária a partir de uma página estática (o CORS bloqueia isso). Salve a página localmente primeiro (Cmd/Ctrl-S, ou copie o código-fonte do DevTools) e cole o HTML em HTML to Markdown. A conversão em si permanece no seu navegador.
A conversão do FormatArc é mesmo só no navegador?
Sim, para a etapa de conversão. O HTML que você cola é processado pela biblioteca JavaScript TurndownAbre em uma nova aba embutida na página, e nenhuma requisição é enviada contendo a fonte. A própria página é carregada de uma CDN por HTTPS e pode fazer chamadas de analytics padrão na primeira visita, mas o HTML que você colou não faz parte de nenhuma requisição de saída.
Resumindo
Para contexto de LLM, o Markdown supera o HTML nos dois eixos que importam: custa menos tokens e deixa o modelo focar no conteúdo em vez da estrutura. A proporção exata depende da página de origem, mas a direção é consistente entre os benchmarks publicados.
Se o HTML de origem for sensível (docs internas, dados de clientes, rascunhos não publicados), a etapa de conversão em si importa. O HTML to Markdown roda localmente no seu navegador, de modo que a fonte nunca chega a um servidor de terceiros.
Para o caminho inverso, veja Markdown to HTML e o guia de Markdown para HTML. Para problemas específicos com tabelas no seu Markdown convertido, a folha de referência de sintaxe de tabelas Markdown cobre escape, alinhamento e armadilhas.