YAML と JSON の違い — 先に結論
ひとことで言うと、API やマシン間のデータ交換には JSON、人が手書きする設定ファイルには YAML を使う、というのが基本方針です。どちらもオブジェクト・配列・文字列・数値・真偽値という同じデータモデルを表現できますが、JSON は厳密で冗長、YAML はインデントベースでコメントにも対応している、という違いがあります。
| JSON | YAML | |
|---|---|---|
| 構文 | 波括弧と角括弧 | インデント |
| コメント | 非対応 | 対応(#) |
| 主な用途 | REST API・データ交換 | 設定ファイル(Kubernetes, GitHub Actions) |
| 読みやすさ | 機械向け | 人間向け |
| 厳密さ | 厳密 | 寛容 |
主要ポイント
- JSON は厳密で高速・機械向き、YAML はインデントベースで人間向きでコメントも書ける
- API・ログストリーム・高スループット処理は JSON、Kubernetes・GitHub Actions・Ansible のような手で編集する設定は YAML
- YAML はコメント・アンカー・マルチライン文字列・日付型を持つが JSON にはない
- LLM プロンプトでは YAML のほうが 10〜25% トークンが少なく済むが、JSON のほうがパースが速く未信頼入力にも安全
この記事では、具体的な構文の違い、同じデータを両方のフォーマットで並べた例、実際の現場での使い分け、そして変換時にハマりやすい落とし穴を順に解説します。2026 年に入ってから増えてきた「LLM プロンプトに渡すならどちらが安いか」という観点にも触れます。
違いを頭で理解するより、実際に変換して見比べるほうが早いこともあります。手元の JSON や YAML を JSON to YAML 変換ツール や YAML to JSON 変換ツール に貼り付ければ、同じデータが両フォーマットでどう変わるかをブラウザ内(アップロード不要)で確認できます。
現場での使い分け実例
構文の話に入る前に、現場で「どちらを選ぶか」の判断はほぼ次のパターンで決まっています。
- Kubernetes マニフェスト、Helm チャート — YAML
- Docker Compose — YAML
- GitHub Actions、GitLab CI、CircleCI の設定 — YAML
- Ansible プレイブック — YAML
- REST API のリクエスト・レスポンスボディ — JSON
package.json、composer.json、ブラウザとサーバー間の通信 — JSON- ログレコードやイベントストリーム — JSON Lines
- OpenAPI / Swagger の仕様 — YAML または JSON(作者は YAML で書き、ツールが JSON を生成することが多い)
パターンは明確です。人間が読む・編集するファイルは YAML、プログラムが生成・消費するデータは JSON。この一言が、フォーマット選択で迷ったときの最良の判断基準になります。
構文を並べて比較する
同じ Web サーバー設定を両方のフォーマットで書いてみます。
YAML:
# Web サーバー設定
server:
host: localhost
port: 8080
debug: true
allowed_origins:
- https://example.com
- https://staging.example.com
headers:
X-Frame-Options: DENY
Strict-Transport-Security: "max-age=31536000"
JSON:
{
"server": {
"host": "localhost",
"port": 8080,
"debug": true,
"allowed_origins": [
"https://example.com",
"https://staging.example.com"
],
"headers": {
"X-Frame-Options": "DENY",
"Strict-Transport-Security": "max-age=31536000"
}
}
}
注目すべき点は二つあります。まず、YAML のほうが括弧や引用符が少ないぶん約 30% 短くなります。そして先頭のコメント # Web サーバー設定 を保持できるのは YAML だけで、JSON に変換すると情報が失われます。
データ型: YAML が持ち、JSON が持たないもの
どちらも文字列・数値・真偽値・null・オブジェクト・配列をサポートしています。YAML はさらにいくつかの型を追加で扱えます。
日付とタイムスタンプ
YAML パーサーは ISO 8601 の日付を第一級の値として受け取ります。
release_date: 2026-04-01
created_at: 2026-04-01T09:30:00Z
JSON には日付型がなく、文字列として扱うしかありません。受け取る側のアプリケーションで自前のパースが必要になります。
{
"release_date": "2026-04-01",
"created_at": "2026-04-01T09:30:00Z"
}
マルチライン文字列
YAML にはマルチライン用の記法が二つあります。リテラルブロック | は改行をそのまま保持し、フォールドスカラー > は改行を空白に畳み込みます。
description: |
このサービスは GitHub のウェブフックを受け取り
内部キューに転送します。
summary: >
すべてのトラフィックは Cloudflare 経由で配信され、
オリジンは 100 rps にレート制限されています。
JSON で同じ内容を表現するには、一行に \n のエスケープで書く必要があります。
{
"description": "このサービスは GitHub のウェブフックを受け取り\n内部キューに転送します。\n",
"summary": "すべてのトラフィックは Cloudflare 経由で配信され、オリジンは 100 rps にレート制限されています。"
}
型の暗黙推論
YAML はクォートされていない値から型を推論しようとします。バージョンによっては yes・no・on・off が真偽値として解釈され、数字に見える値は数値になります。人間が書くときは便利ですが、予期せぬバグの温床にもなります。有名な例が「ノルウェー問題」で、country: NO が真偽値 false として扱われてしまうケースです。JSON はすべてが明示的なので、こういった罠は起きません。
コメント: YAML の設定ファイル向け強み
YAML のコメントは # から行末までです。「なぜこの設定が必要なのか」を残すのに非常に便利です。
retries: 3 # これ以上は上流のタイムアウトを超えてしまう
JSON にはコメント構文がありません。"_comment": "..." というフィールドを入れる、あるいは標準外の JSONC / JSON5 を使うといった回避策があるのは、この制約を補うためです。詳しくは JSON にコメントを書く方法 を参照してください。
アンカーとエイリアス: YAML の再利用機能
YAML は値を一度定義して別の場所から参照できます。& でアンカーを打ち、* でエイリアスを参照し、<<: のマージキーで共有ブロックを取り込みます。
defaults: &defaults
adapter: postgres
host: db.internal
pool: 5
development:
<<: *defaults
database: myapp_dev
production:
<<: *defaults
database: myapp_prod
pool: 20
これを JSON に変換すると、アンカーはインライン展開され、development と production がすべてのデフォルト値を複製して持つ形になります。データとしては正しいのですが、「共通のデフォルトを使っている」という元の意図が JSON 側では読み取れなくなります。
パフォーマンスとサイズ
マシン間のデータ転送という観点では、JSON のほうが速いです。JSON.parse・json.loads・encoding/json のように、主要言語は高速な JSON パーサーを標準装備しています。YAML のパースは文法が複雑で曖昧さもあるため遅く、多くの YAML ライブラリは内部的に JSON 相当のツリーを構築しています。
ファイルサイズは YAML のほうが 20〜30% 小さいことが多いのですが、転送前に gzip を通すとその差はほぼ消えます。YAML の本当のコストはバイト数ではなく、パースの CPU 時間と、暗黙の型推論が引き起こす予期せぬ挙動のほうです。
YAML を選ぶべきとき
- ファイルを人間が読む・手で編集する
- データペイロードではなく設定ファイル
- 設定の意図を残すためにコメントが必要
- Kubernetes・Docker Compose・Ansible・CI など、既に YAML を前提にしているツールチェーンの一部
- アンカーやエイリアスで重複を減らしたい
手元の JSON を YAML に書き換えて読みやすくしたい場合は JSON to YAML 変換ツール にそのまま貼り付けられます。ネストとコメントの位置をブラウザ内で確認できます。
YAML を使うべきでないとき
YAML が向いていそうに見えても、実際には逆効果になるケースがあります。
- マシン生成の設定ファイル — 型推論で
version: 2.0が数値2になるなど、データが黙って壊れる - リアルタイムのデータストリーム — パースのオーバーヘッドが無視できない
- セキュリティ上信頼できない入力 —
!!python/objectのような YAML タグで任意コードが実行される危険。必ずyaml.safe_load相当を使う - 短くフラットなペイロード — インデントで得られるはずの短さがなくなり、JSON のほうが素直
JSON を選ぶべきとき
- データを生成・消費するのはプログラム
- 言語をまたいだ相互運用性が必要で、予期せぬ型変換を避けたい
- API でデータを送受信する
- 厳密でブレのないパースを求めている
- パフォーマンスが重要で、パースが速く予測可能である必要がある
人が書いた YAML を機械が処理できる JSON に渡す場面は実務で頻出します。YAML to JSON 変換ツール なら、構文エラーは行番号付きで指摘されるため、型推論で壊れた値も発見しやすいです。
YAML を JSON に変換するときの落とし穴
変換はほぼロスレスですが、いくつか注意点があります。
- コメントが消える — JSON にコメント構文がないため
#で始まる行はすべて失われる - アンカーが展開される — 共有ブロックがコピーされ、データが重複する
- 日付が文字列になる — ISO 形式の日付は型情報が失われる
- 型推論の意外な結果 —
version: 2.0のような YAML は JSON では数値2になる - マルチドキュメント —
---で区切られた複数ドキュメントは JSON では扱えず、どれか一つを選ぶか配列でラップする必要がある - 重複キー — YAML の挙動は実装依存だが、JSON では最後の値だけが残る
- タグや独自型 — YAML の
!!timestampや独自タグには JSON 側に対応物がない
詳しくは YAML を JSON に変換する方法 を参照してください。変換後の JSON を読みやすい形に整える具体的なコツは JSON 整形のコツと注意点 にまとまっています。
FormatArc で YAML ⇄ JSON を変換する
FormatArc はブラウザ内で変換を完結します。アップロードも会員登録も不要で、データは手元から出ません。
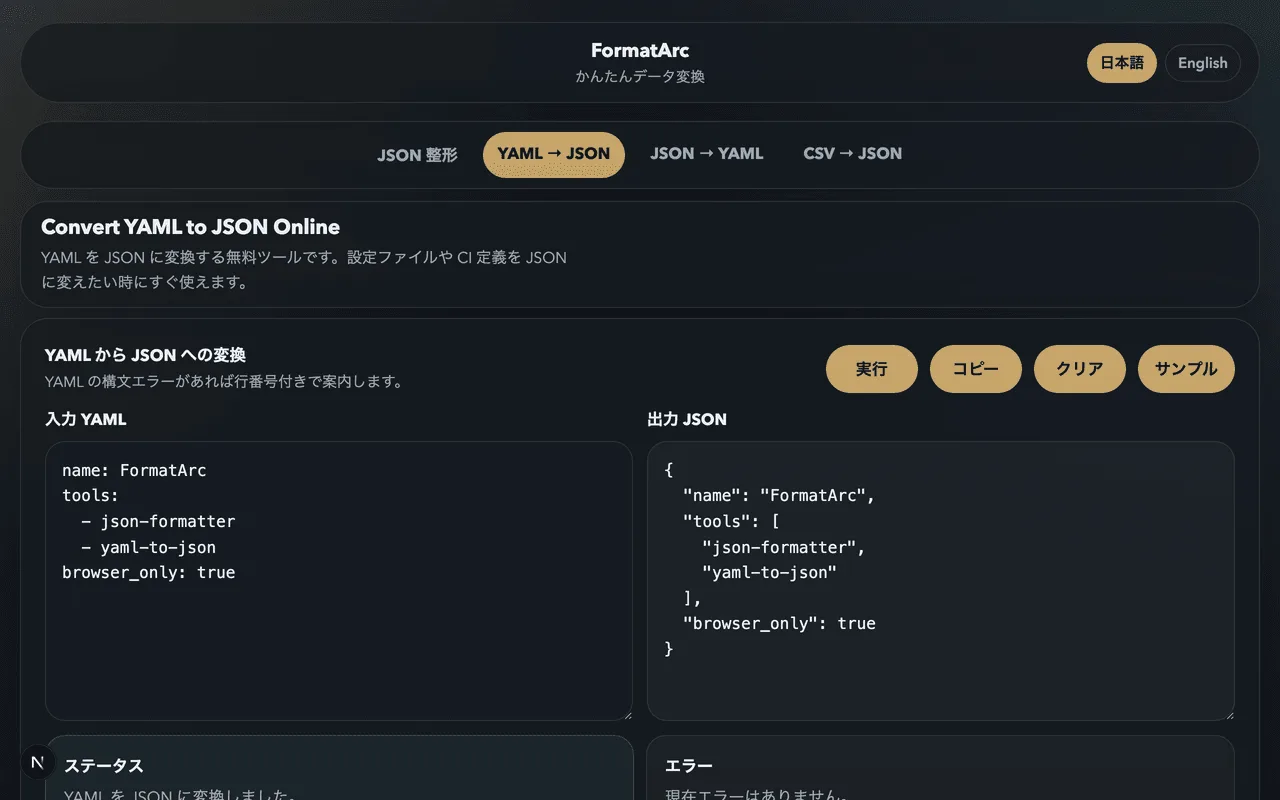
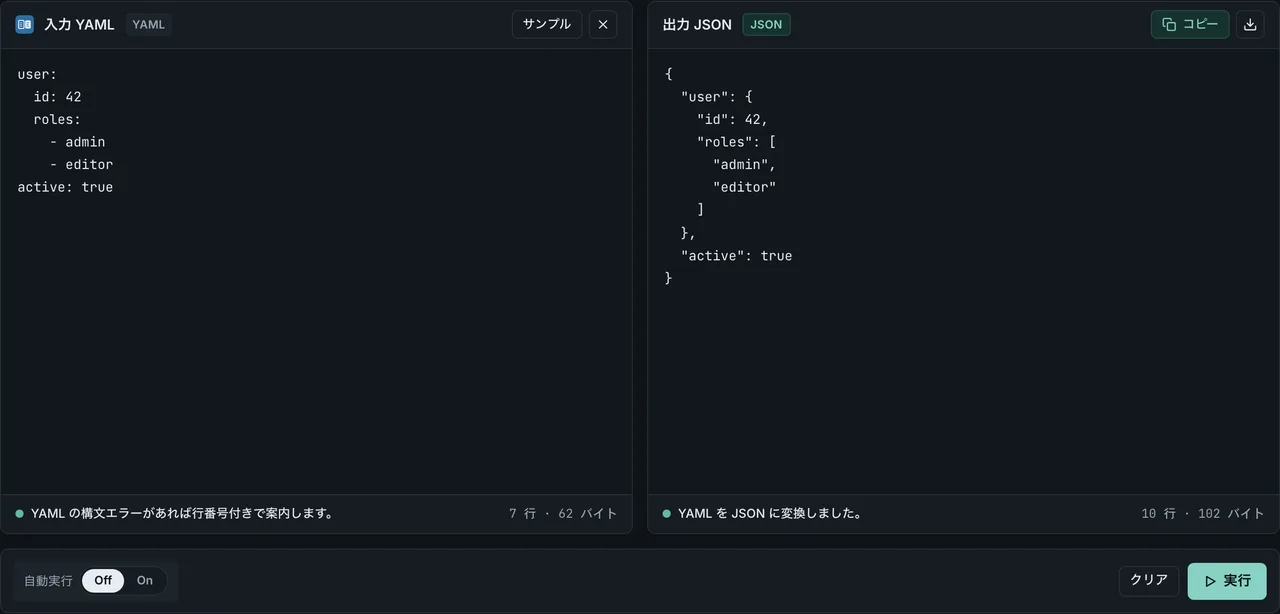
- YAML to JSON — YAML を貼り付けて JSON を得る。構文エラーは行番号付きで表示
- JSON to YAML — 逆方向の変換。ネストを保った綺麗な YAML を出力
- JSON Formatter — 変換結果の JSON を整形・エラー表示する
スクリプトで処理したい場合は yq や Python の yaml.safe_load が定番です。Python のワンライナーなら次のとおりです。
python3 -c "import yaml,json,sys; print(json.dumps(yaml.safe_load(sys.stdin),indent=2))" < config.yaml
よくある質問
YAML は JSON のスーパーセットですか?
YAML 1.2 以降、正しい JSON はそのまま YAML としてもパースできます。つまり YAML パーサーは JSON ファイルを読めますが、逆はできません。ただし多くの YAML ライブラリは古い YAML 1.1 をデフォルトにしているため、この互換性は完全ではありません。
なぜ Kubernetes や Docker Compose は JSON ではなく YAML を採用しているのですか?
設定ファイルを人間が手で編集することを前提にしているからです。インデントベースでコメントも書ける YAML のほうが、長大な設定を保守しやすいためです。状態を出力するときは kubectl get ... -o json のようにマシン向けの JSON モードを別途用意しているケースがほとんどです。
YAML は JSON より高速ですか?
いいえ、JSON のほうが大幅に高速です。主要言語の JSON パーサーは高度に最適化されており、YAML は文法が複雑な分だけ遅くなります。パフォーマンスが重要なデータ転送では JSON のほうが有利です。
JSON を YAML に変換するとデータは失われますか?
通常は失われません。JSON のほうが機能が少ないため、JSON → YAML はほぼロスレスです。元から JSON にないコメントを追加することはできませんが、データ自体は問題なく往復できます。JSON to YAML 変換ツール をブラウザで試してみてください。
YAML で country: NO と書いたら false になってしまうのはなぜですか?
有名な「ノルウェー問題」です。古い YAML パーサーは引用符で囲まれていない NO を真偽値 false として解釈してしまいます。country: "NO" のようにクォートすれば解決します。YAML 1.2 ではこの挙動は仕様から削除されましたが、多くのツールは依然として 1.1 をデフォルトにしています。
LLM プロンプトに渡すなら YAML と JSON のどちらがトークン効率が良いですか?
多くの場合は YAML のほうが安く済みます。OpenAI の cl100k_base や Anthropic のトークナイザは波括弧・角括弧・繰り返される引用符を別トークンとして数えるため、深くネストした JSON は構造の分だけトークンを消費しがちです。同じデータで比較すると、YAML のほうが 10〜25% 程度トークン数が少なくなるのが典型的です。ただし、モデルによっては厳密な JSON 出力のほうが安定することもあります。2026 年時点でよく見るパターンは「入力は YAML、出力は JSON を指定」という組み合わせです。
YAML のコメントは JSON への変換後に残りますか?
残りません。コメントはファイル内の行に紐づいた情報であり、パースして構造化データになった時点で失われます。JSON に変換してから復元する方法はないので、コメントを残したい場合は変換前の YAML を保管しておくのが最善です。
関連記事
- YAML を JSON に変換する方法 — 実例付きの変換ガイド
- JSON を YAML に変換する方法 — 逆方向の変換
- YAML とは — YAML の基本
- YAML の書き方ガイド — ゼロから正しい YAML を書く
- JSON 整形のコツと注意点 — 変換後の JSON を読みやすく整える
- JSON にコメントを書く方法 — JSONC・JSON5・回避策
- JSON とは — JSON の基本
まとめ
- YAML と JSON は同じデータモデルを表現します。違いは「誰が読むか」にあります
- 手で編集する設定ファイルには YAML、機械間でやり取りするデータには JSON
- 変換時は型推論・アンカー展開・コメント消失に注意してください
- FormatArc ならブラウザ内で双方向の変換と行番号付きエラー表示が使えます