Word や Google ドキュメント、Web ページからコピーした文章をエディタに貼り付けたら、<span style="..."> や class="c3"、<o:p> といったタグだらけになった経験はないでしょうか。文章自体は入っているのに、Markdown のレンダラーには不要な装飾用マークアップに埋もれてしまっている状態です。この記事では、その汚れた HTML を一手間でクリーンな Markdown に変換する方法を紹介します。
まず結論から
汚れた HTML を HTML to Markdown に貼り付けて実行ボタンを押すだけです。span、inline の style 属性、class 名、<font> タグ、Word 由来のマークアップは Markdown に対応する書き方がないため取り除かれ、見出し・リスト・リンク・表といった構造だけが Markdown として残ります。処理はブラウザ内で完結するので、社外秘の資料を貼り付けても外部に送信されることはありません。
HTML クリーナーとの違い
「inline style を除去する」系のツールや HTML クリーナーが返すのは、あくまで clean HTML です。装飾は落ちますが、<p> や <ul> といったタグは残ったままになります。貼り付け先が README、GitHub の Issue、Wiki、あるいは LLM へのプロンプトであれば、欲しいのは Markdown なので、もう一歩足りません。
変換ツールはこの 2 つを同時に行います。装飾ノイズを取り除いたうえで、#・-・[テキスト](url) といった Markdown 構文を出力します。HTML をきれいにしてから変換する、という二度手間が不要です。
なぜ貼り付けた HTML は汚れるのか
汚れ方はコピー元によって変わります。出どころごとに混入するノイズの種類が違います。
Microsoft Word
Word はコピーしたテキストを Office 独自のマークアップで包みます。style 属性内の mso-* プロパティ、段落を示す <o:p> タグ、条件付きコメント(<!--[if gte mso 9]>)、<font face="..."> タグなどです。いずれも読者にとって意味を持たない情報です。
なお、混入するマークアップはコピー経路によって変わります。Word のデスクトップアプリから直接貼り付ける、Outlook を経由する、ブラウザで開いた Word ファイルからコピーする、それぞれで出力されるタグの量や種類が異なり、軽いこともあれば重いこともあります。
Google ドキュメント
Google ドキュメントはセマンティックなタグよりも inline CSS に寄った出力をします。太字が <strong> ではなく <span style="font-weight:700"> になっていたり、自動生成された class 名や、文字のひとかたまりごとを包む空の「ゴースト span」が大量に挿入されたりします。class 名は自動生成のため、特定の名前が必ず付くと当てにはできません。
Web ページのコピー
表示中の Web ページの一部を選択してコピーすると、そのサイトがレイアウトに使っていたものを丸ごと持ち込みます。ラッパーの <div>、ユーティリティ用の class 属性、inline の style、ときには欲しかった本文の隣にあったナビゲーションのリンクやシェアボタン、広告枠まで付いてきます。Markdown に変換すればレイアウト層は捨てられ、読みやすい構造だけが残ります。
ChatGPT やリッチテキストエディタ
チャット UI や WYSIWYG エディタから整形済みの回答をコピーすると、エディタ固有の span や data-* 属性を含んだ HTML になることがあります。それを別のツールに貼ると汚れが引き継がれますが、Markdown に変換すれば中身だけが残ります。
何が削除され、何が残るのか
代表的な汚れたマークアップと、変換後にどうなるかを表にまとめます。
| 元のマークアップ | 例 | Markdown での結果 |
|---|---|---|
| inline style | <span style="color:#333">text</span> | text(style は削除) |
| class 名 | <p class="c3 c7">text</p> | text(class は削除) |
| Word の Office マークアップ | <o:p></o:p>、mso-* style | 完全に削除 |
| font タグ | <font face="Calibri">text</font> | text |
| ラッパーのコンテナ | <div><span>text</span></div> | text |
| 空 / ゴースト span | <span></span> | 削除 |
| data 属性 | <p data-id="9">text</p> | text |
| 見出し | <h2>Title</h2> | ## Title |
| 太字(意味的 / style 指定) | <strong>x</strong> または <span style="font-weight:700">x</span> | **x** |
| リンク | <a href="/p" class="btn">go</a> | [go](/p) |
| リスト | <ul><li>a</li></ul> | - a |
ここで 2 点おさえておきたいことがあります。
- Markdown は HTML よりも表現できる範囲が狭い言語です。構造としての対応物がある要素(見出し・リスト・リンク・強調・表・画像)は保持され、純粋に装飾目的のものは落とされます。
- 「Markdown に変換する」ことは「HTML がゼロになる」ことを保証しません。Markdown の仕様は inline HTML を許容しているため、変換ツールはうまく対応付けられないタグ(複雑な表や未対応の要素など)を、中身を捨てる代わりに生の HTML 片として残すことがあります。結果は十分にクリーンですが、あらゆる場面で
<span>が必ず消えるという約束ではありません。
FormatArc で汚れた HTML を変換する
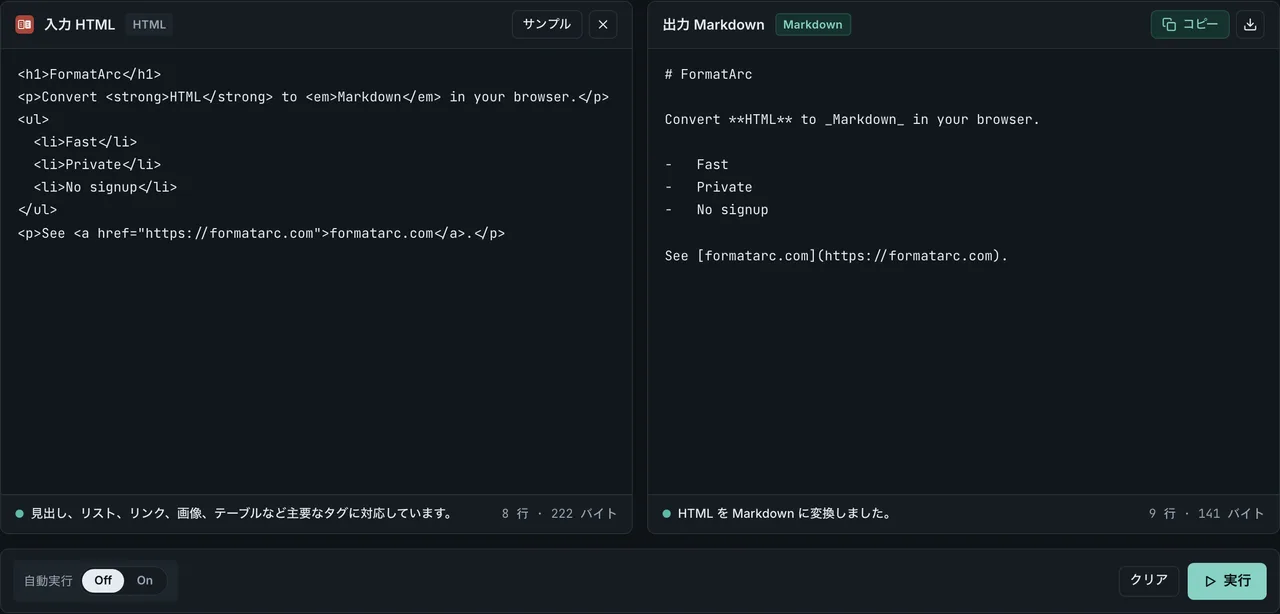
HTML to Markdown は、貼り付けた HTML から Markdown を生成します。インストール不要で、何もアップロードされません。
- HTML to Markdown を開きます。
- 左側に汚れた HTML を貼り付けます。Word のゴミやゴースト span ごとそのままで構いません。
- 実行ボタンを押すと、右側にクリーンな Markdown が表示されます。
HTML の解析も Markdown の生成もブラウザ内で動くため、Word から貼り付けた社外秘の契約書や CMS の未公開ドラフトも手元に留まります。FormatArc や第三者に送信されることはありません(その仕組みについては オンライン変換は安全か で詳しく解説しています)。
きれいに変換できないとき
いくつかのパターンは、もう一手間が必要です。
Word の表と罫線
Word やスプレッドシートから貼り付けた表は、colspan や rowspan、罫線のスタイルを含むことが多く、これらはパイプ表に対応する書き方がありません。結合セルは平坦化され、表そのものが inline HTML のまま残ることもあります。表だけを変換したい場合は HTML テーブルを Markdown に変換 でエッジケースを扱っています。
ネストしたリストと改行
深くネストしたリスト、リスト項目内の <br>、順序付き・順序なしが混在したネストは、余分な空行が入ったりインデントが平坦化されたりすることがあります。出力を確認し、レンダラーで崩れる場合はインデントを手で直してください。
出力に残った inline HTML
<sub> や複雑な表、<details> ブロックなど一部の HTML が残った場合、それは仕様どおりの挙動です。変換ツールが中身を捨てずに残しているためです。Markdown は GitHub や多くの静的サイトジェネレータで inline HTML をそのままレンダリングするので、残したままでもよいですし、手で削除しても構いません。混在した Markdown がどう表示されるか確認したいときは Markdown to HTML に貼り付けてプレビューできます。
Web コピーで混ざるナビゲーション
ページの広い範囲をコピーしてメニューやシェアボタンが混ざった場合は、コピー前に範囲を狭めるか、Markdown 出力から余分なリンクの羅列を削除してください。どのリンクがナビゲーションでどれが本文かを自動で判別する方法はありません。
よくある質問
なぜ span や style 属性は削除されるのですか
Markdown には inline CSS や class 名、ラッパーの span を表す構文がないため、変換ツールはそれらを落として構造的な内容だけを残します。これが目的です。エディタ固有のノイズを抱えた HTML ではなく、どのレンダラーでも読める移植性の高い Markdown が得られます。
Microsoft Word の mso- マークアップも除去されますか
はい。mso-* の style プロパティ、<o:p> タグ、<font> タグ、条件付きコメントは Markdown に対応物がないため除去されます。Word が出力するマークアップはコピー方法によって変わりますが、いずれも Markdown としては残りません。
class 名やスタイルを保持できますか
いいえ。Markdown では表現できないため、意図的に取り除かれます。スタイルが必要な場合は元の HTML を保存しておき、構造は Markdown に変換したうえで、表示時に Markdown to HTML で CSS を当て直してください。
社外秘の資料を貼り付けても安全ですか
安全です。変換は JavaScript でブラウザ内のみで動き、貼り付けた HTML が FormatArc や第三者のサーバーに送信されることはありません。ブラウザ完結型ツールの確認方法は オンライン変換は安全か で解説しています。
変換後の Markdown に HTML が残っているのはなぜですか
Markdown は inline HTML を許容するため、変換ツールは対応付けられない構造(複雑な表や未対応のタグ)を、中身を削除する代わりに生の HTML 片として残します。残したままでも、手で削除しても問題ありません。
まとめ
Word・Google ドキュメント・ChatGPT・Web ページから来た汚れた HTML は、HTML to Markdown に一度貼り付けるだけでクリーンな Markdown になります。span・inline style・class・Office マークアップは落ち、構造は残ります。HTML から Markdown への変換全般(CLI での方法も含む)については HTML を Markdown に変換するガイド を、LLM にクリーンな内容を渡したい場合は LLM のための Markdown と HTML 比較 を参照してください。